

How To / Tutorials
Designing a Virtual Assistant
Introduction
Using the WHY, WHAT, HOW principal, we will take you through a guideline on how you can design a virtual assistant (VA). Virtual assistants can help many different stakeholders of an enterprise and an enterprise can choose to have multiple assistants to target these different constituents. It is important to start with the WHY so that WHAT can be designed accordingly.
Amongst the many things to be considered while deciding on the application of virtual assistants, one of the key considerations is the end consumer that will actually get this assistance. The end consumer group could be your customer, your employees, your partners. Even within the customers, different approaches can be taken based on the line of business like in a bank there could be retail or HNI or business customers.
The WHY First
The WHY and WHO are intertwined in the case of VAs and hence we recommend that you start with these two elements first and together. When adopting and scaling digital is a prerogative across all enterprises, VAs are at times thought of as yet another way of reaching out to clients just like internet portals and mobile applications are and just like your competition is doing. Yes, they are yet another way to reach out to your customers digitally, but the engagement levels and channel coverage it can provide can be phenomenally different and the experience can and should be completely reimagined and not replicate the internet and mobile.
So starting with the WHY and the related WHO considerations, the following points could be the started:
- Do we need a VA for a better experience of our prospects who visit our websites and find it difficult to find a product that suits their requirements? Or maybe they know what they want but just don’t know how to apply or which documents to submit? Are we losing prospects in the middle of an on-line application process? So website navigation for your prospects and customers may be the could be the problem statement that you need to solve in this case through a VA. An additional requirement here is to help reduce the dropout rates by providing timely help.
- Are our customers finding the existing digital channels difficult to use and reaching out to our contact centers a lot more than desired? Are they not able to get their services requirements fulfilled through the internet portal and mobile application even if those are available? So reducing your assistance requirement through human-intensive channels is the prerogative
- Is reaching out to a certain segment of customers through digital channels difficult because they are still not comfortable with navigation and would rather communicate in their native language which they can easily do through the call-center and the branches? So providing conversational native language support to reach out to these segments is the objective here. Other additional considerations could be reaching them through channels like Whatsapp, FB Messenger and so on which they anyway frequent rather than the enterprises own digital properties. Or maybe voice support for those that find typing difficult through Google Assistant or even in an application with voice-enabled.
- Are your sales agents/partners/staff not finding the right products to fit the customer's requirements at the point of sale? Do they need tools to make the product features and eligibility clear to their prospects who are sitting in front of them? Similarly, contact center agents could also be searching for answers keeping the customer on hold. To assist your prospects and customers, your sales and service agents/staff could be needing a VA to have all the information at their fingertips
- Are your employees finding it difficult to find answers to their queries on policies and processes within the organization? Are your support departments like HR, Finance, Admin, IT finding it difficult to serve the queries raised by the employees? A VA within your collaboration tool Microsoft Teams or Slack could just be the virtual employee that can serve this need of other employees and reduce turn-around times drastically.
These are a sample set of consumers and the related reasons for the requirement of VAs. The design of your VA will largely be driven from these problem statements and the consumers who are facing them.
WHAT Comes Next
For each of the problem statements above a different kind of VA design can be followed. Some of the problem statements like those mentioned in 1-3 are targeted to the same constituent and hence a VA can be designed for one of them or all of them together. The important point to remember is that VAs can also be designed incrementally to solve more problem statements as you go along and need not be designed for everything on day one. A phase-wise approach could start with an FAQ or website navigation for prospects as Phase 1 and can then be designed for other capabilities for your customers like service requests in Phase 2 and Inquiries and Transactions in Phase 3 and more Inquiries, Transactions and Service Requests in Phase 4 and so on. Similarly, a channel-wise approach can also be taken as well as a combination of channels and functionality is also possible. An enterprise can start with the VA on its website, next, take up providing that facility in mobile application and internet banking, go onto FB Messenger, Whatsapp, Alexa, and Google Assistant next and so on. Or the order of channel enabling can be completely different based on business drivers/country level adoptions etc.
The platform approach of Active.AI for conversational channels makes the implementation journey simpler since the underlying use cases and related conversational flows remain the same and can be tweaked for channels through simple configurations.
Some of the considerations for what is to be designed in the customer VA are:
- What kind of calls and queries coming into contact centers and branches? Which of them have the highest volumes?
- What is the highest volume of searches on your website?
- Where are your website visitors spending most of the time?
- Where is the maximum turn-around time for transactions on the internet and mobile application?
- From which segment/region do you have most customers reaching out to the contact center and branches? Do you have a demographic profile of such customers?
- Do you have a large number of followers on your FB page? Do your customers use that channel to reach out to you?
- Are you already using messenger channels like Whatsapp for communicating with your customers? What is the volume of subscribers on such channels?
- Are voice channels like Alexa / Google Assistant have a large customer base in your country/region / amongst your customers? Are there projections/trends visible to you on the adoption of those channels?
- Are you trying to provide VA for your customers in 2 or more languages?
For design and prioritization of internal use VAs, the considerations can be:
- Which department spends the most time on its internal customers (employees) queries? Identify the areas within the department that attracts the highest level of human intervention
- Should you provide the VA as a separate channel on your intranet or should it be a virtual employee in your collaboration platform (MS Teams, Slack, etc.) or both. Or should this be added to the enterprise mobile application?
- Do you need a VA for your customer-facing personnel (call center agents, sales representatives, direct selling agents, etc.) to help out with customer queries? Through which channel can you provide the VA?
HOW Do You Achieve All This
This last section on VA design describes at a high level how to go about building your VA on Active.AI conversational AI platform. This will also provide a reference to the various other sections of the overall document where the details of a particular step are specified.
Once you have decided on the purpose and what goes into VA, the following steps can be followed to build up the VA:
- Since the VA will represent your brand, especially if it’s for your customers, it should reflect the brand ethos of your enterprise. Define the persona of the VA starting from a name and physical attributes. Involve your marketing and communications departments to build up the persona. Starting from gender (or maybe gender-neutral or non-human) to age (millennial, gen X or Y or Z, or maybe completely indeterminable) to serious or witty to chatty or to the point. All of these can be designed through the Small Talk module of the platform ( refer section xyz), the UX design (refer section xyz),the welcome message (time dependant like Good Morning or festival greeting and so on) the responses given by the VA for different actions (refer section xyz) and the design of the templates (refer section xyz). The brand color and logo to be used in the user interface (UI) can also be decided at this stage.
- Depending on what you want to provide on your own digital properties like your website, mobile application and logged in internet portal for your customers you can configure and customize the user interface of those channels. Other channels can be designed based on the features available on the channel. Various UI options are available to decide upon like a set of static quick links, dynamic options based on queries, acceptance of usage terms and conditions. Some of these can also be provided in some of the external channels. Refer section xyz for details.
- Decide on the first set of FAQs you want to go live with. This can be based on the data you already have. Curate the answers so that it can lead to related questions and lead generation. Various options are available to curate the answers for conversational channels like a call to action, image-based answers, links and videos and so on. Refer to the section on FAQs for all the options that are available on the platform.
- Design other queries that do not require the user to login but require specific API calls like ATM and Branch Locator, Lead Generation, Call Back request and so on. Various options are available to design such workflows with Google Maps and other application integration. Refer details in section xyz.
- Other options like market data, stock quotes, news, weather, etc can also be integrated and provided without having the user to login. In case you want to design and build those refer to the section on custom use cases.
- The next thing to work on would be the list of inquiries, service requests and transactions to be fulfilled through the conversational mode. The availability of APIs will be a key consideration for prioritization and planning of implementation in phases. Reimagine the workflows and do not always replicate the flow you have internet and mobile applications. Remember conversational experience can provide a lot more ease of use and deeper engagement. Simplified flows that can serve 80% of the cases are preferable and possibly redirect to mobile or internet for the other 20% exceptional cases instead of making the entire flow more complex. Refer to business application sections to design your conversational flows. Also, design the variations required in different channels due to channel limitations or the mode of conversation like voice or messenger. For each of the use cases, design the responses based on VA persona and the functionality. Use can use text, images, and templates. Several options are available here to design such responses.
- Since most of the inquiries and transactions require authentication, design the login experience and integration. You can use your existing authentication mechanisms and multi-level authentication as well based on conditions. The logged in experience can start with a more personalized greeting since the customer is identified at this stage. Personalized campaigns can also be designed for deeper engagement or cross-selling.
- A key setup for the accuracy level of your VA is the assimilation and training of utterance data. We provide out of the box data for the financial services domains like retail banking, business banking, capital markets, and insurance. These data can be further enhanced with your existing live chat data or any other customer interaction data like call-center transcripts. Other data that needs to be assimilated are your enterprise-specific product names, FAQs and so on. See sections on Data Management and FAQ setup.
- The closure of the conversation can also be designed in various ways. It can be a combination of goodbye, option to send a transcript of the conversation, a personalized message or even a campaign.
- You can design emoji-based feedback at every step or selected step on the VA performance and accuracy. We recommend you do this for FAQs.
- You can also provide tips on how to make the experience in the conversational channel more delightful or how to correct in case incorrect data is entered.
- Since AI is never 100% accurate, you should design a fallback for the VA in case it cannot understand the query. The Fallback can be done in steps and is completely configurable. The first level fallback could be a response stating that the VA is not able to understand and if the user can reword or select from the suggestions provided. The next level could be an offer to redirect the query to a human agent seamlessly. In the same VA UI, the human agent interaction can be designed. Please refer to the section on Fallback.
- To use advanced AI features like context change, compound queries, sentiment analysis and so on refer to the section on Triniti. These features can be configured and training data to be provided to enable them for your VA. Some examples are :
- Compound Query :
Utterance - Show me my balance and transfer 50K to Mom. In this case, there are 2 intents in a single utterance and both are to be fulfilled. The VA can be configured to handle this and the corresponding responses and flow can be designed - Context Change:
Utterance at a transfer confirmation stage where the original utterance had 50K - Change amount to 5K. VA can be designed to take a reconfirmation with the new amount. - Sentiment Analysis :
Utterance: Your credit card services are horrible. Your VA can understand a negative sentiment and often the subject of the sentiment. The response can be designed to sympathize with the user and offer to transfer to a human agent or at the first level ask for more details on the subject of the negative sentiment and then transfer the context to the human agent.
- Compound Query :
All these points are detailed out in the various sections of this document. You can use some or all of these features and can also bring them in gradually in phases. Also, see the section on how to keep on improving the VAs accuracy through different modes of learning.
Building a bot
Lets start by building a conversation AI enabled bot in 5 easy steps as shown in the diagram below -
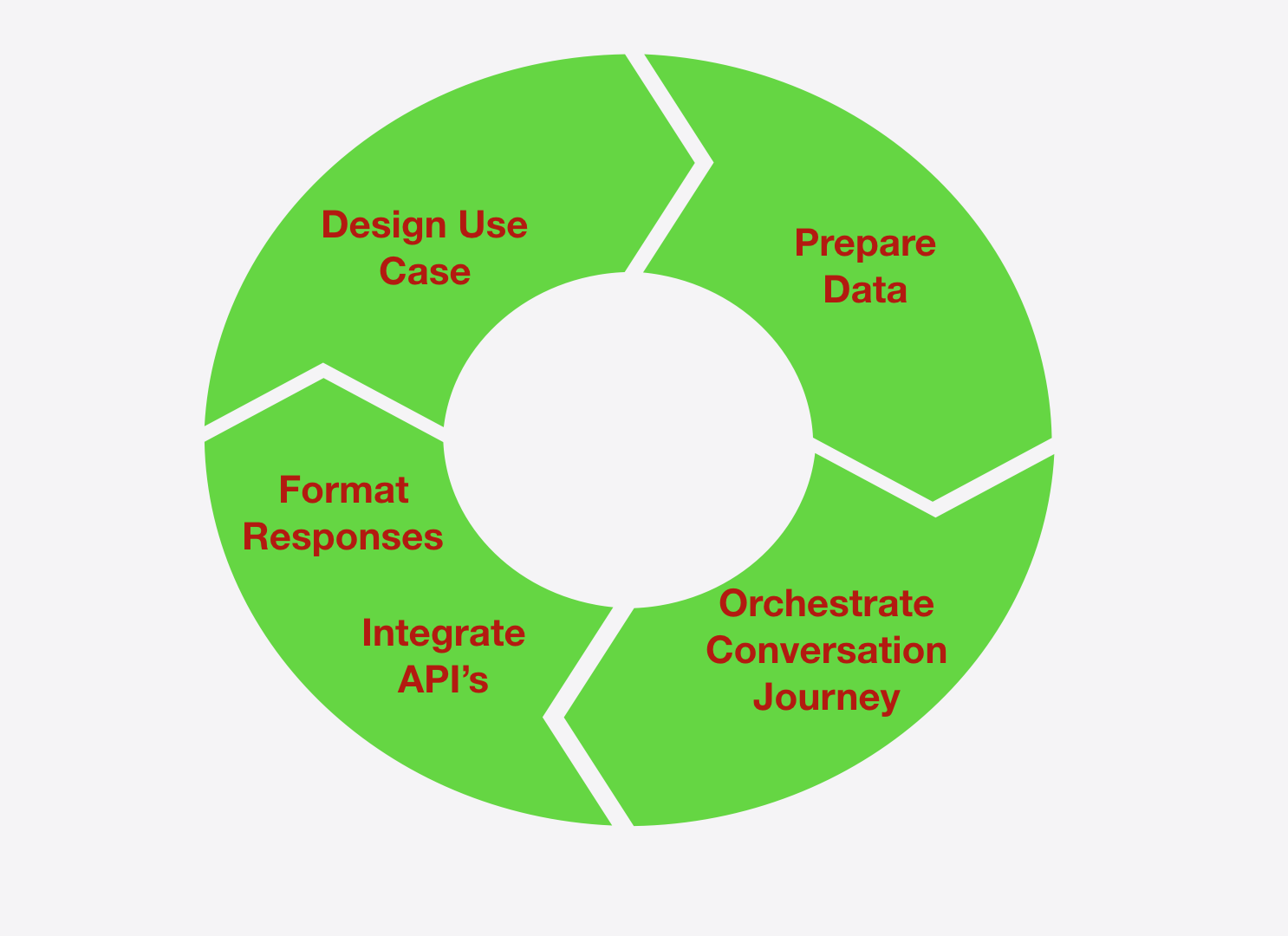
Design Use Case
Defining and desiging use cases are the first task that one do. Please refer to the the detail tutorial on this.
Prepare Data
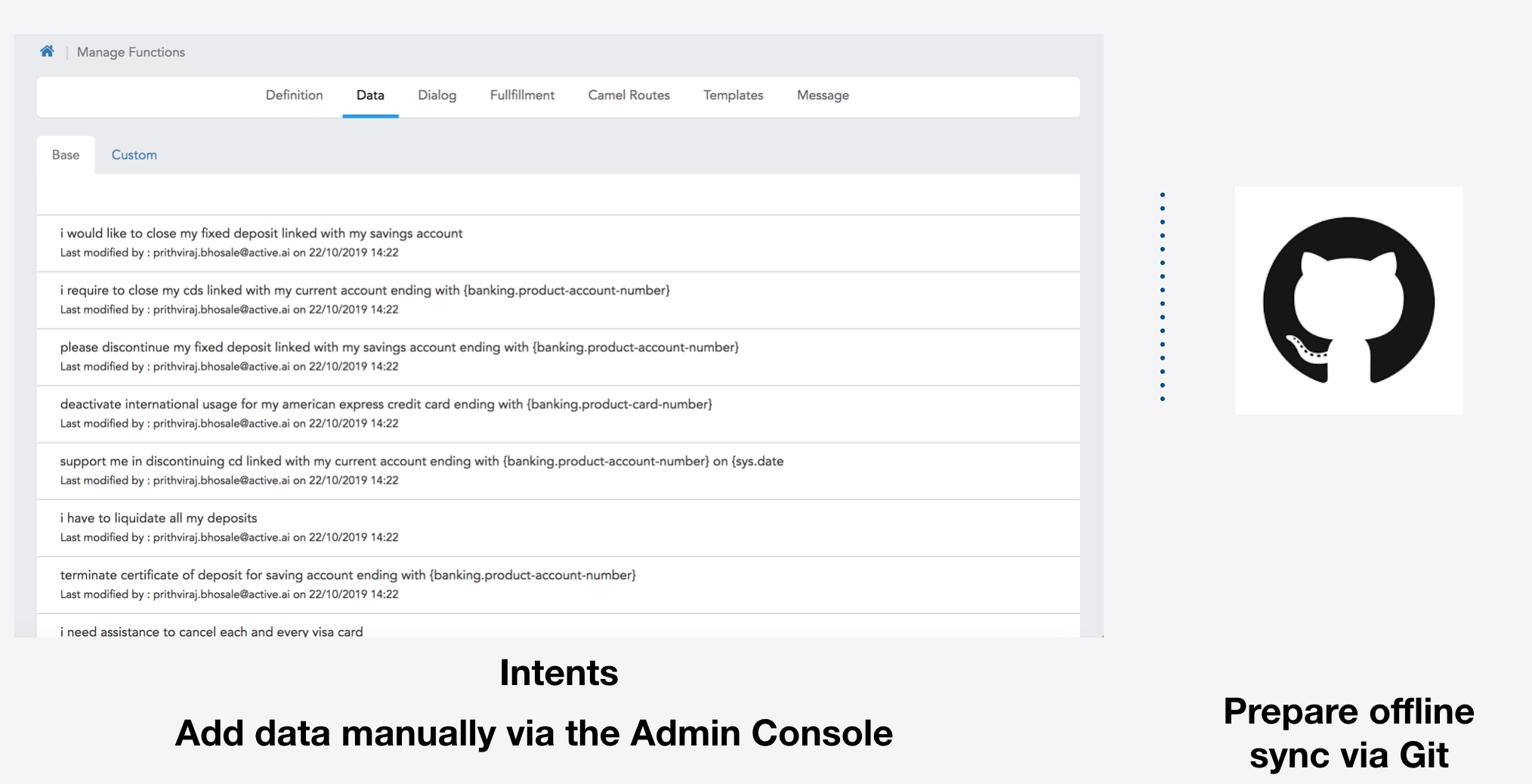
You can prepare data manually using our Admin Console and you can also prepare the data offline and sync with our own flavoured Git workflow.
Refer to respective data preparation section using Admin and Git for a detail tutorial on how to achieve this.
Conversational Journey Design
Craft unique conversational journey based on your use-case. There are many ways to achieve this in Morfeus platform, please refer to this Workflow
and Webhook tutorials for details.
Integrate API’s
Define your own responses using the Webhook, you can call any external API, we will handle the response and shape the conversation.
Format Responses
Template Editor gives you a way to create a rich media in-conversations in the bot which is not the usual text messages - per channel per language). Refer to the detail tutorial on how to format responses.
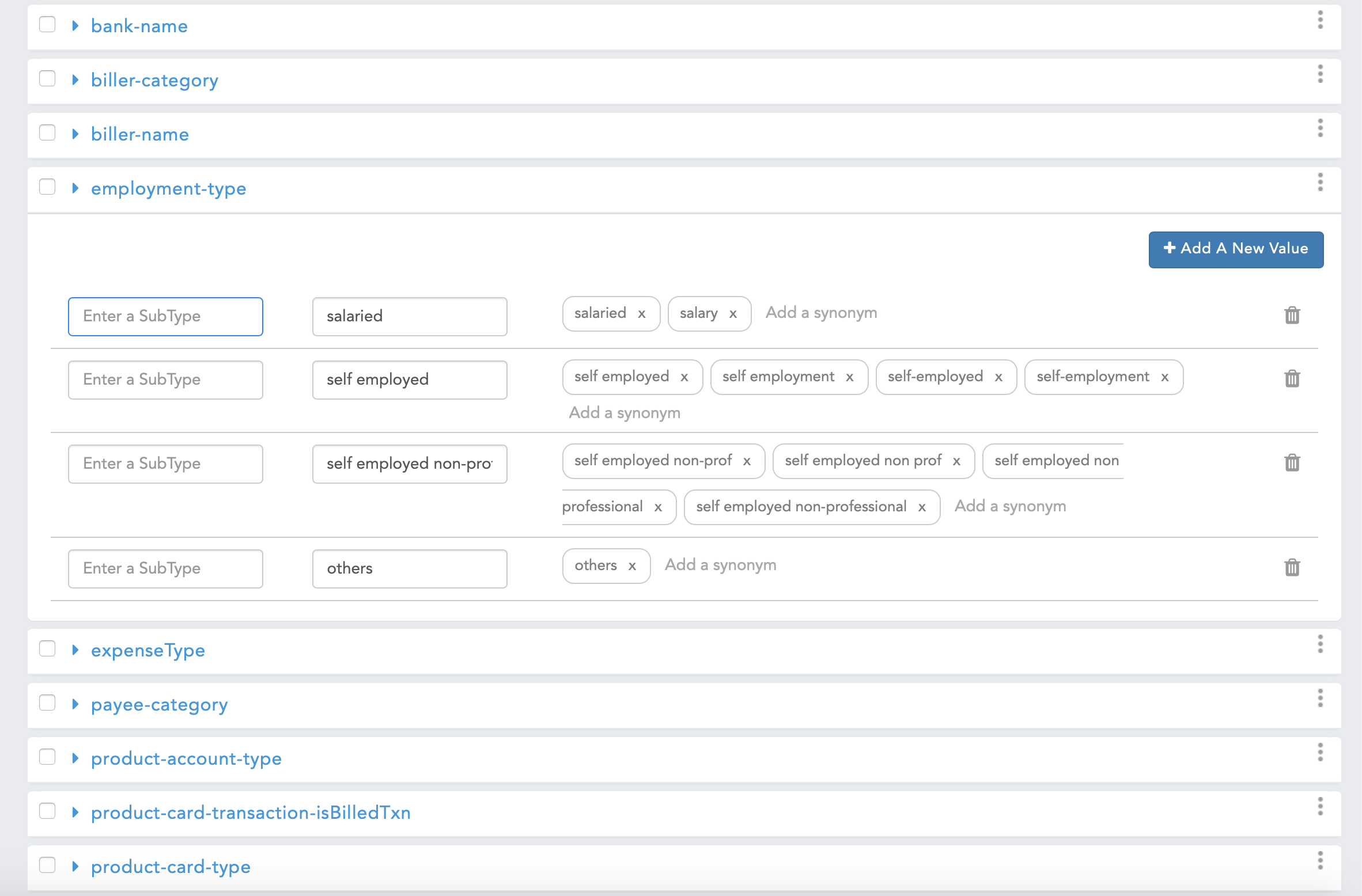
Defining Use Cases
The very first step in training the bot is to identify all the use cases for the domain. This is the most critical step, it is important not to mix up use cases with intents at this stage of thinking.
Step-by-step guide
- Customer requirements should be divided into small logical blocks of use cases.
- Each use case should be divided in a way that it contains all the unique ways a user can express his interest in the query or transaction.
- It is important that while designing the use cases, all product requirements are kept in mind instead of the scope of a particular phase. This will avoid the possibility of redesign at a later stage.
- Utterances in each use case should follow the following guidelines:
- It should include a good mix of simple utterances (one - few words eg. get quote) to complex ones like (eg. I want to know the nav of ICICI Prudential mutual fund today).
- The utterances should be grammatically correct
- The data should include synonyms of important words (eg. for mutual fund quote - nav, price,value, quote, all refer to the same thing and should be included)
Good and Bad Examples of UseCases
GetQuote (Get price of a security) can be thought of as one customer requirement. However, it could include the price of different securities including mutual fund, equity, derivatives, indices, etc. Hence its a good idea to divide the requirement into smaller use cases like: 1. Get quote Equity 2. Get quote mutual fund 3. Get quote indices and so on. This structure will help scale the use cases easily for other products at a later stage and also manage the data more easily.
File Naming Convention
Use Case file are named in the following format
<LANGUAGECODE>_<DOMAIN>_<USECASENAME>_.txt
File Format
User Asks for Quote of a Mutual fund
intent=qry-securityquote entities=globalmarkets.security-type,globalmarkets.security-name,globalmarkets.security-identifier,globalmarkets.exchange-name,globalmarkets.exchange-code,sys.date,sys.country modifiers=52wkhigh,7daylow,6monthreturn [Utterances] NAV Price Net Asset Value Quote Value Purchase value Purchase price Cost Show me the NAV Show me the price Show me the Quote
FAQ
Q. I have two use cases that are very similar. Should I keep them together. A. No. Even though they are very similar, keep them separate to ensure logical separation. This is also useful when in future versions of triniti, we will support sub-intents. Q. Can more than one use cases have the same intent A. Yes, more than one use cases can have the same intent.
Typical Symptoms
Symptom : Particular Intent is getting misclassified a lot. Solution : Symptom : An Entity is never getting extracted for an intent. Solution :
Managing Fullfillment
Workflows
Workflow Editor
The Workflow Editor as the name suggests is a GUI to create/edit a new/existing workflow.
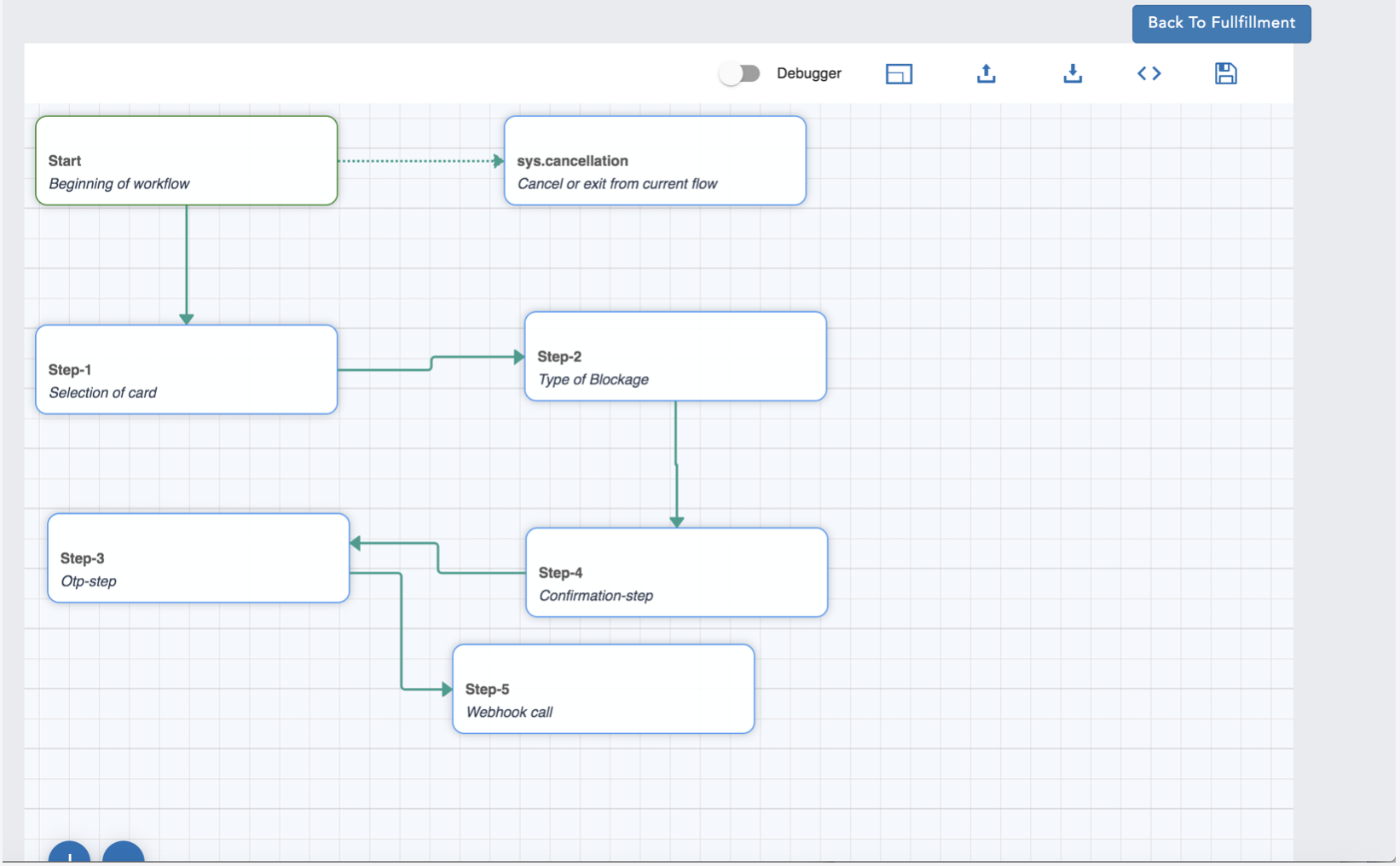
Workbook
A workbook is where you will design the complete flow for a particular intent. Each workbook can have multiple nodes to define the flow. The figure below shows a new workbook with the default Start & Cancel nodes and the toolbar.
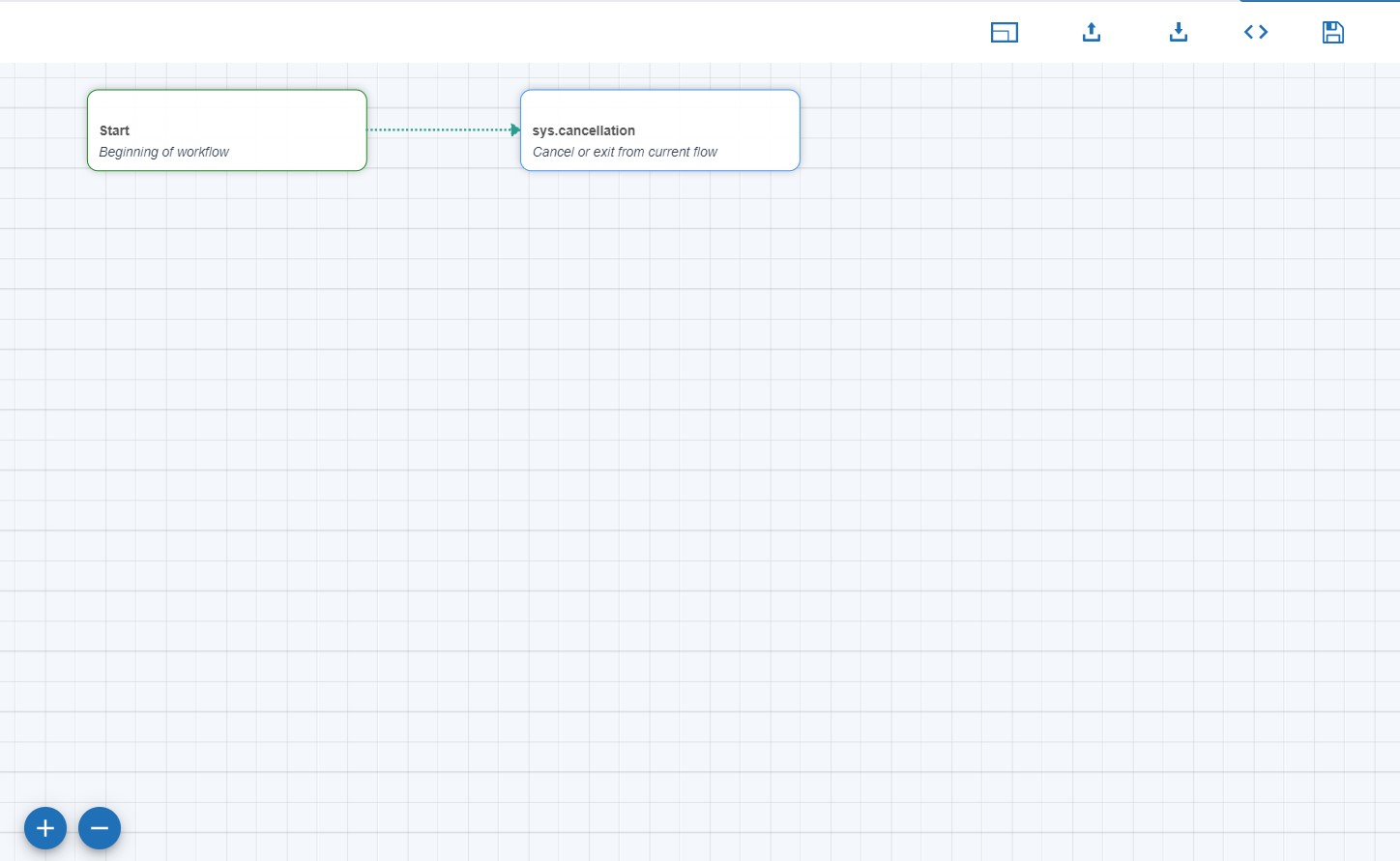
Toolbar
Toolbar exists in the top right corner of the workflow editor, which comprise of
Debugger Toggle: To enable/disable debugger.
 Full Screen: To make the editor occupy full screen or go back to the standard window.
Full Screen: To make the editor occupy full screen or go back to the standard window.
 Download: To downloads the AIFlow file. The AIFlow file can be imported for other intent or in the other workspace.
Download: To downloads the AIFlow file. The AIFlow file can be imported for other intent or in the other workspace.
 Upload: This can be used in case a pre-designed AIFlow file is available and needs to be uploaded to show a workflow in the editor.
Upload: This can be used in case a pre-designed AIFlow file is available and needs to be uploaded to show a workflow in the editor.
 Save Workflow: To save the workflow.
Save Workflow: To save the workflow.
Node
Node is one step of the process to complete a flow. Each node is attached to one entity. Moreover, every node has three responsibilities.
- Ask input from the user
- Verify inputs
- A route to the next node
Each node except the start node has four buttons on the right-hand side upper corner to open Definition, Validation, Connection and to delete. For the start node, there is no Validation. Tiny “garbage can” icon on every node enables the user to delete a particular node selectively.

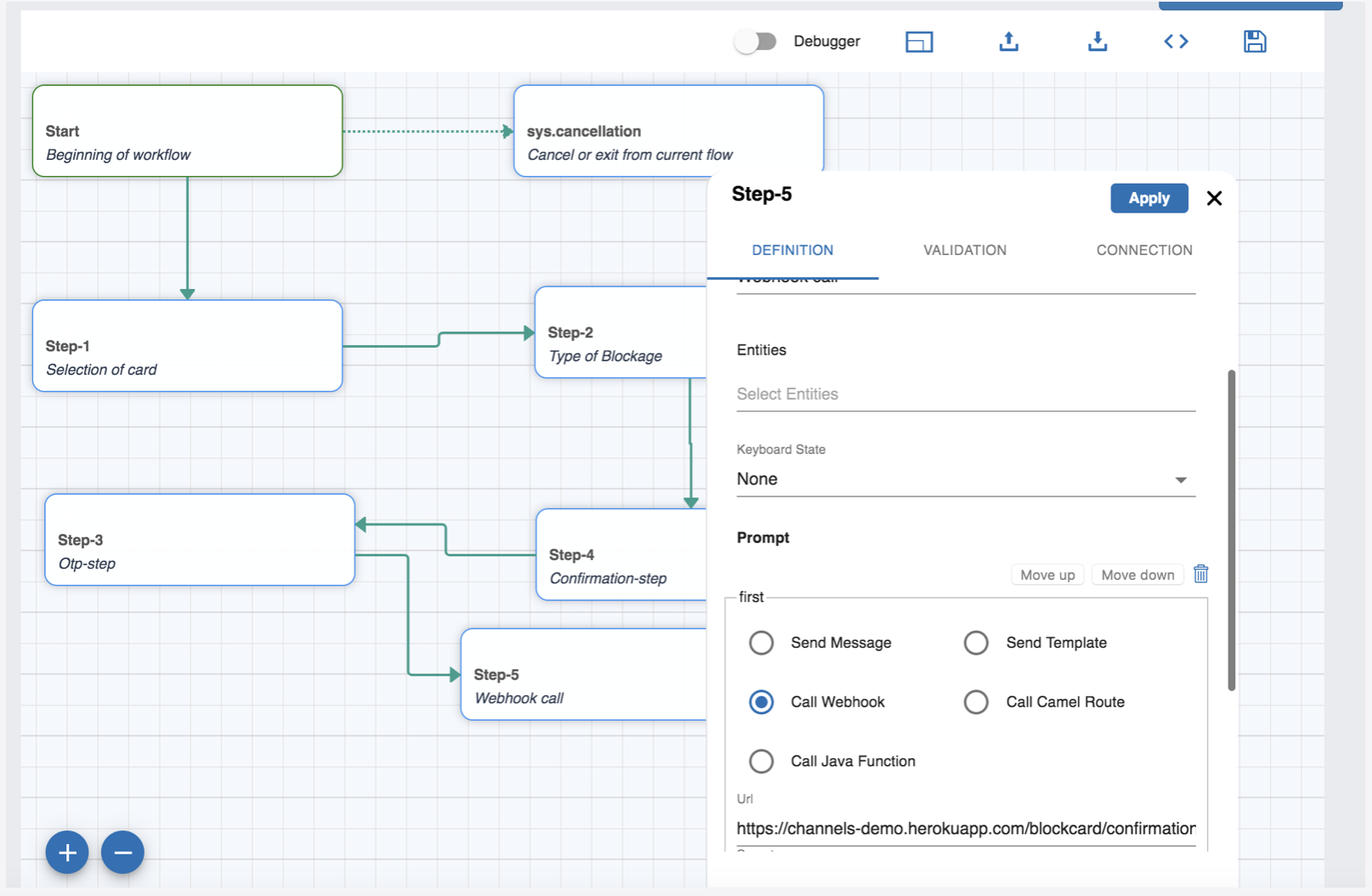
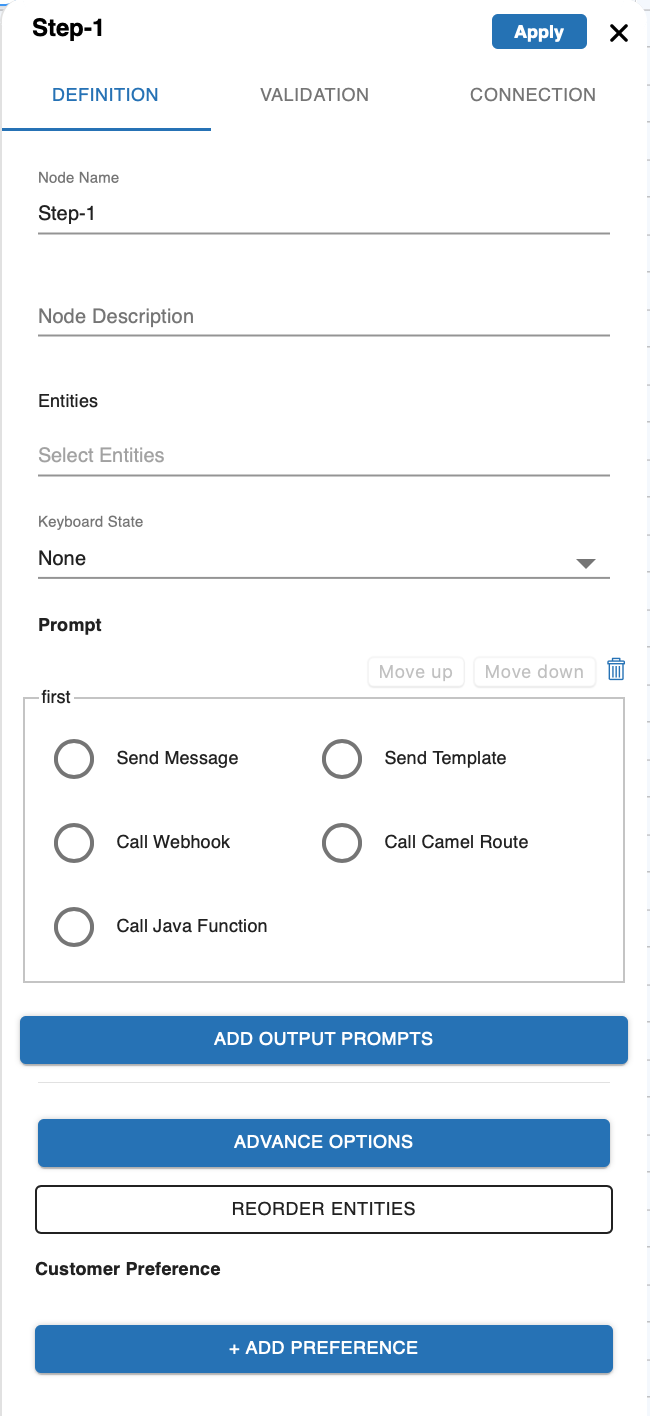
Definition Tab
This category contains the following keys (as can be seen from the attached fig below) :
| Table 1 Definition Tab | |
| Node name: name of the node. Node description: a brief description of what the node does. Entities: The entity to be handled by the node. Keyboard State: hint for the channel to update the keyboard state. Not all the channels support that. Prompt: Messages to send to the user to ask for the entities. See Prompts for more information. |
 |
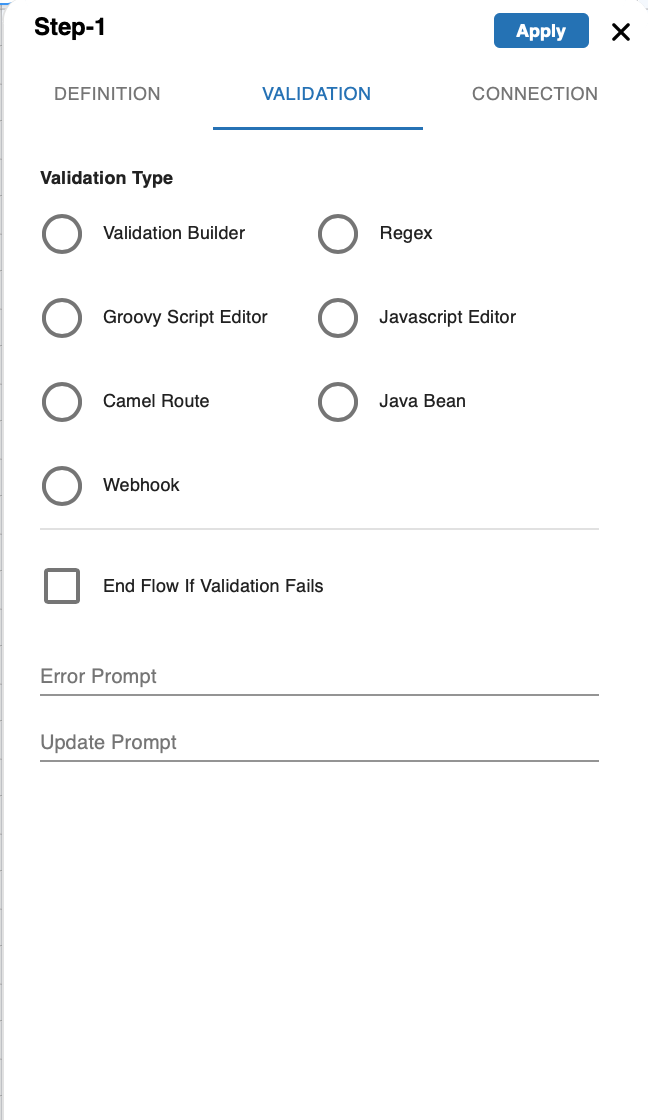
Validation Tab
This category contains the keys participating in the validation of user inputs:
| Table 2 Validation Tab | |
| Validation Type: defines the type of validation of the user inputs e.g. regex validation, camel route validation, etc. End flow if Validation Fails: if checked, the flow will end altogether in case the validation of the current node fails. Error Prompt: this static error text message is displayed if the user fails the validation. Update Prompt: this static text message is displayed if the user updates the value. See Handling Validations for more information. |
 |
Connection Tab
This section can be configured to have conditional branching to another node and is reflected in the script section of the input definition in JSON.
| Table 3 Connection Tab >> Handling connections | ||
| See Handling Connections for more information. | 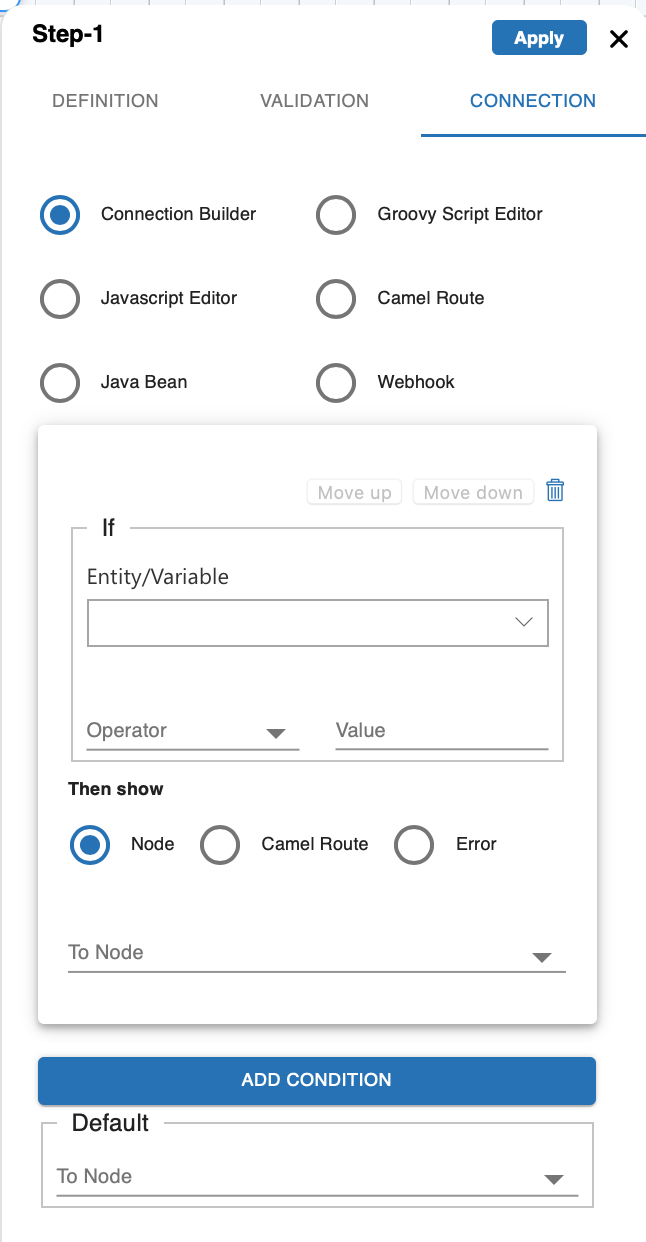 |
|
Defining a Workflow
Workflow helps to define conversation journeys. The intent and entity might be enough information to identify the correct response, or the workflow might ask the user for more input that is needed to respond correctly. For example, if a user asks, What is the status of flight? defined workflow can ask for the flight number.
In a workflow, each entity is handled by a node. A node will have at least a prompt and a connection. A prompt is to ask for user input and connection to link to another node. In a typical workflow which handles n entities, there would be n+2 nodes (One node per entity with a start and a cancel node). Even though while designing a workflow we expect user inputs in a sequence, but by design, a workflow can handle any entities in any order or all in a single statement. It out of the box supports out of context scenarios or updates and many other features. See Features to check the list of workflow features.
Sequence of Execution
The workflow like any other bot conversation starts with an utterance made by the user, followed by Triniti's intent identification and consequently followed by the start/init node of the workflow.
Every node has the jobs of slot-filling (getting the entity value from the user), validating user input and moving on to the next node.
As one might imagine, to fulfill above process, each node has a "prompt" to ask a user for an utterance (to get the entity it is expecting), a "validation" process to validate the entry and finally a "connection" to jump to another node to further the flow.
Hence, the Sequence of implementation involving User and Workflow is:
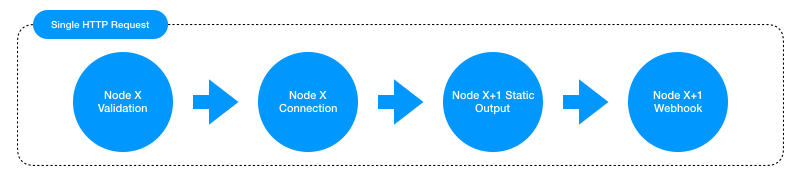
Sample Scenario:- 1) User says: I want to book a flight from Delhi to Singapore.
2) Since the workflow has been configured as the fulfillment of the intent identified here (let's say "txn-bookflight"), the init (start) node is called. The connection of this node is executed, and the next linked node is called. (Hence the start node has only "connection")
3) The node connected to the start node gets called by the "connection" part of the start node. Let's call this node X for easier understanding. For this node (and all nodes from hereon) first prompt is executed.
4) Prompt has the responsibility of prompting the user to enter an utterance to resolve and expected entity for the current node (node X).
5) Once the user enters the utterance, validation of the X node is executed to validate the entity value entered by the user as part of the text.
6) On successful validation, the control moves on to connection of node X, where a logical decision is made to know which node to branch on from the current node (X).
7) On successful execution of connection, the underlying framework has now resolved the node to be branched onto. Let's call this node X+1.
Now steps 4 through 7 will be sequentially executed for each node until the user ends the flow or there is some failure in any of the above steps or the flow itself ends successfully.
Find the detailed description of Prompts, Validations and Connections in the following text.
Prompts - User Input
Prompt defines how to ask for the required information or reply to the user. You can define it in the following ways:
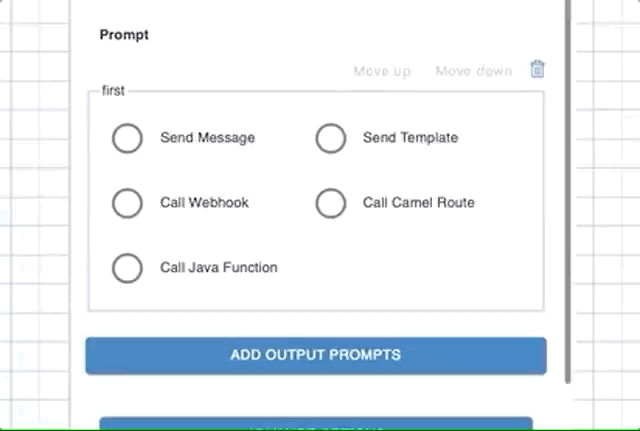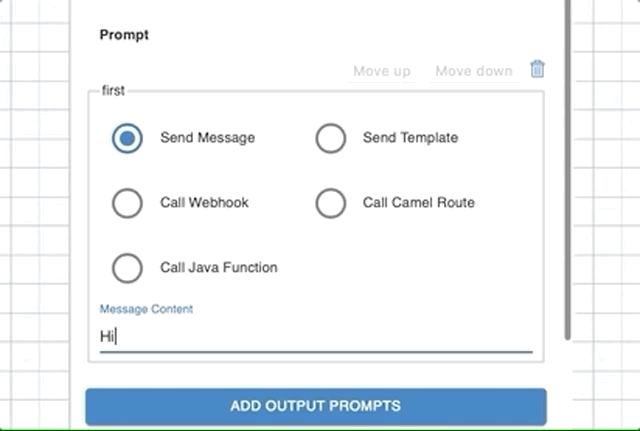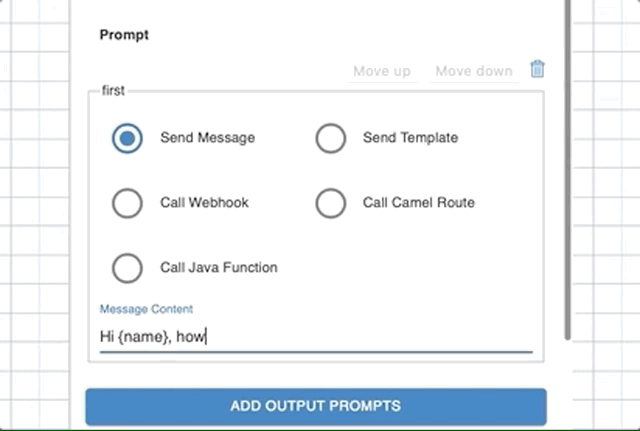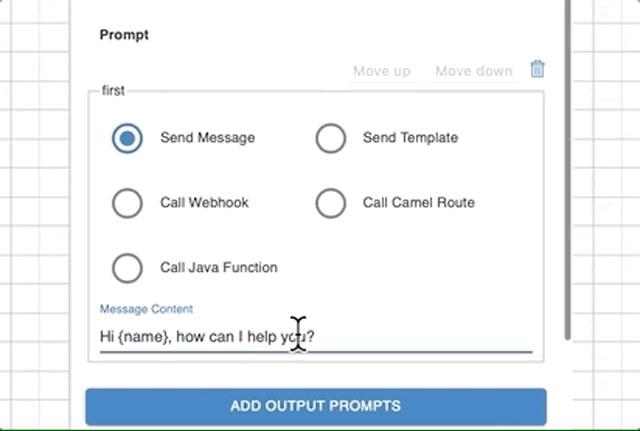
Send Message
If you want to respond with a text message, choose Send Message options and add a message in Message Content text box. A message can include workflow variables using curly braces.
For example, if you have name as a variable in the workflow context, to use it in the message, your message would look like Hi {name} , how can I help you?
Send Template
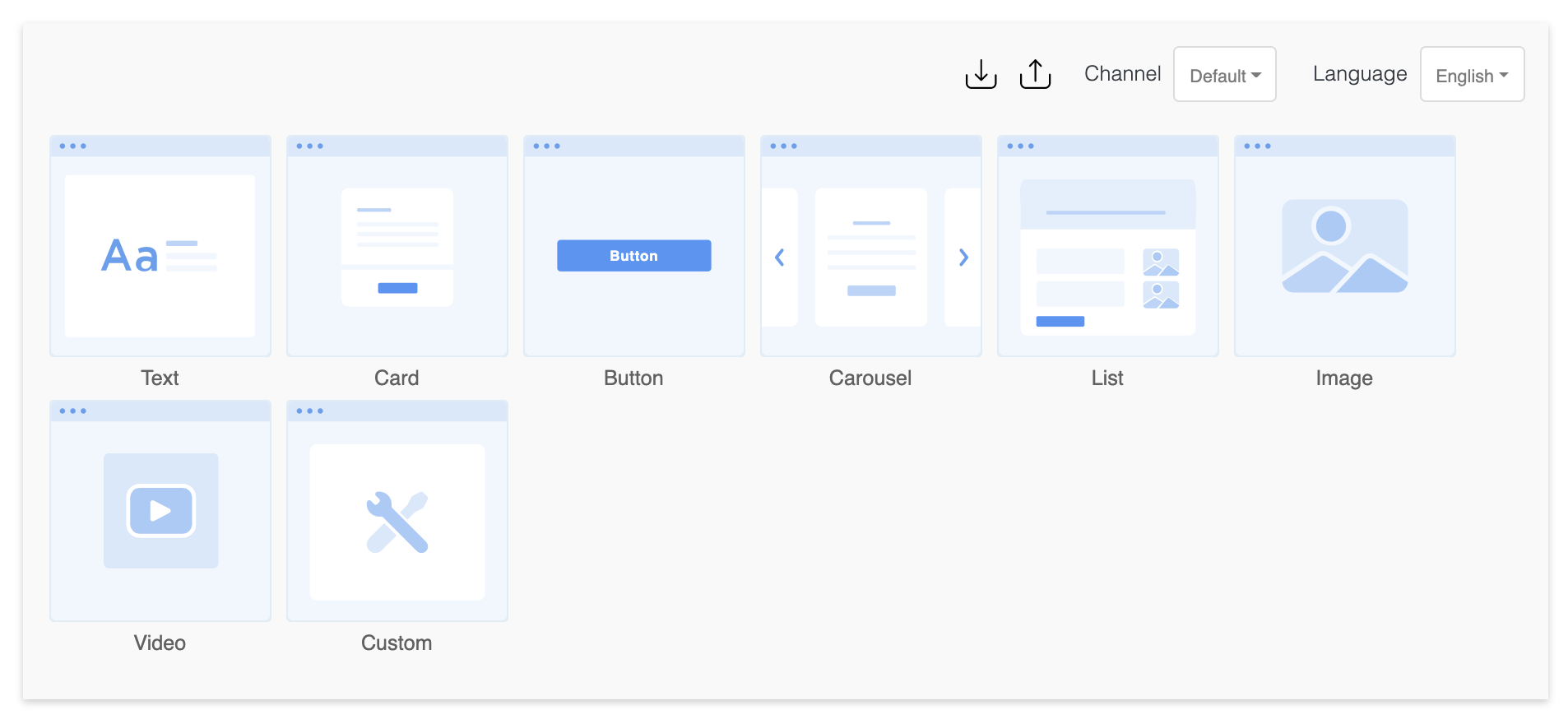
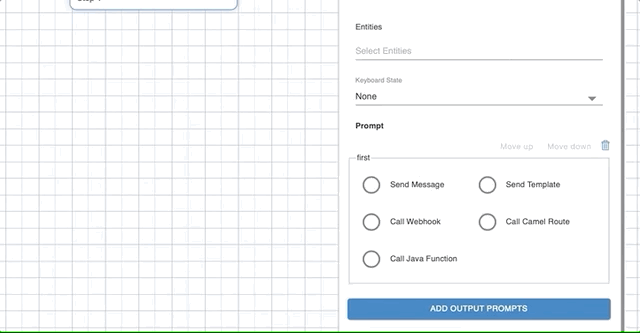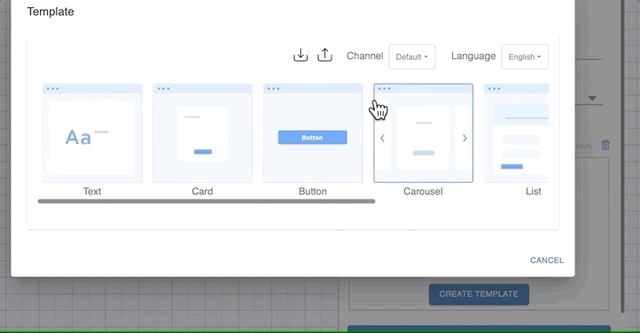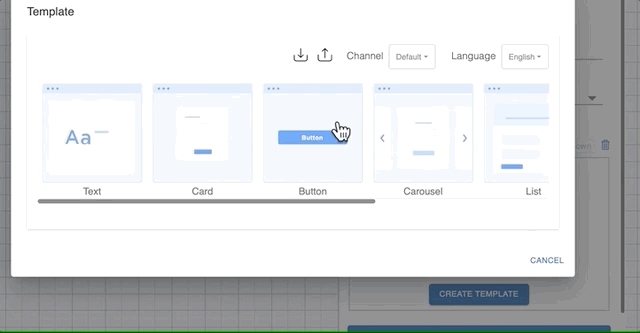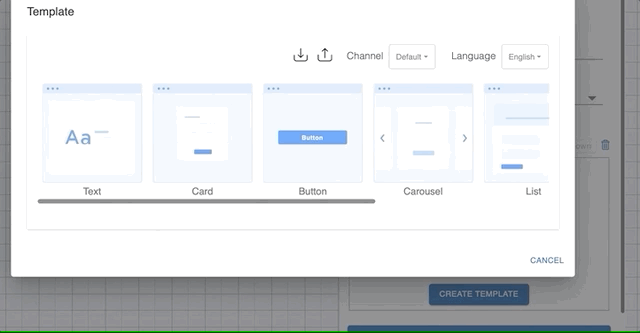
Sometimes it’s a better user experience to ask or show information using templates. For that you have the option to choose from:
- Card
- Buttons
- Carousel
- List
- Image
To use one of the templates as prompt, choose to Send Template in a prompt and click the ‘Create Template’ button. That will show you a dialog like in the figure below. See Templates for the complete list with details.
Call Webhook for Prompt
You can define a webhook to return a dynamic response. Webhook defined will get a request with the event workflow_webhook_pipeline. See Webhooks for more information.
Call Camel Route for Prompt
Morfeus uses Apache Camel for integrations. You can define a camel route to return a dynamic response. See Camel Routes for more information.
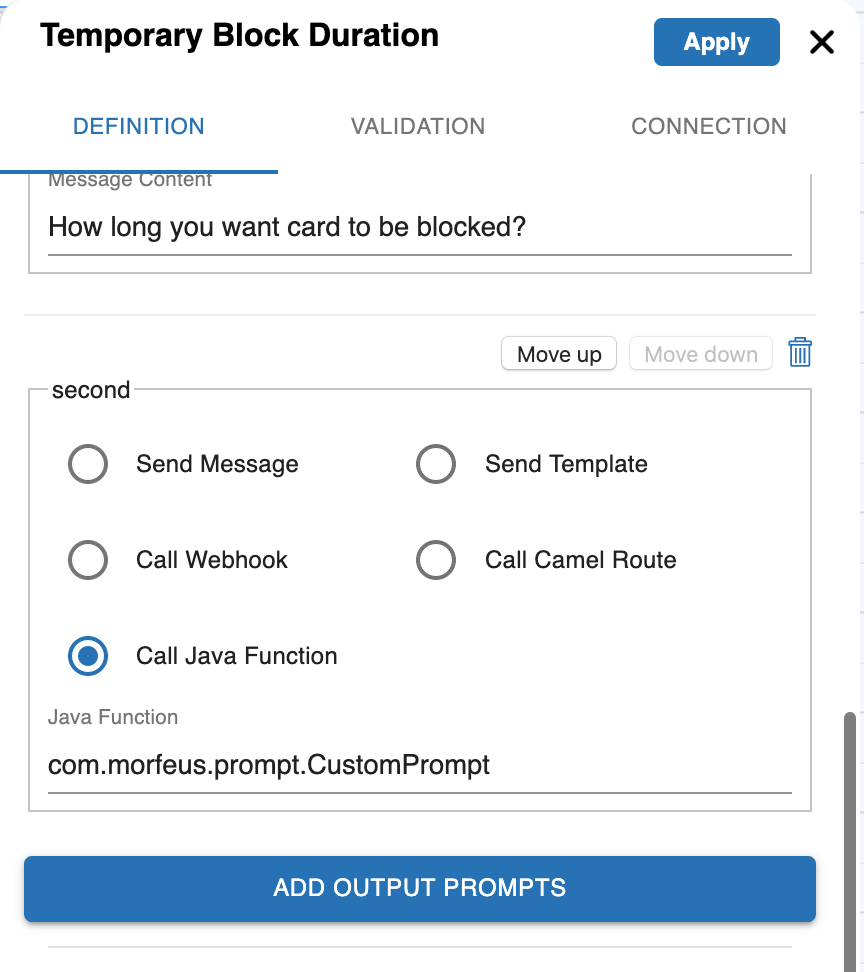
Call Java Function for Prompt
You can define a Java Bean to return a dynamic response. Your class is to implement interface com.morfeus.workflow.base.Pipeline. Your class to be packaged in a Jar file and to be added in the external jar folder of the application server. You can either create Spring bean of the class or Morfeus will manage the instance creation. In the workflow, you need to provide the class name with the package name.
public interface Pipeline {
ResponseMessageWrapper process(final CMM cmm, final WorkflowRequest workflowRequest);
}
Validations
If you want to validate user input before proceeding to next node, you have option to do that using one of the following:
- Regex
- Groovy Script
- JavaScript
- Webhook
- Validation Builder
- Camel Route
- Java Bean
Validation using Regex
For a typical node that expects a single simple entity like mobile number or email etc, you can use a regex to validate the input. For example, if you expect only Gmail email addresses as an input, you can use define a regex like ^[A-Z0-9._%+-]+@gmail\\.com$. Any valid Java regex will work.
Validation using Groovy Script
You can define the validation code in Groovy script. Request and workflow variables are exposed along with the Webhook request object as wRequest (Refer WorkflowRequest class in GitHub). Groovy validation script needs to return status (success/error) with other optional fields like workflow_variables and global_variables as JSON response.
Sample Groovy Script
import groovy.json.JsonSlurper
import java.text.SimpleDateFormat
import java.text.DateFormat
import java.util.Date
import java.text.ParseException
if (sys_date != null) {
DateFormat df = new SimpleDateFormat("dd-MM-yyyy");
Date now = new Date()
try {
Date date = df.parse(sys_date);
if (date < now) {
return new JsonSlurper().parseText(' {"status":"error"}')
} else {
return new JsonSlurper().parseText(' {"status":"success", "workflow_variables": {"travel_date": "' + date.format('yyyy-MM-dd') + '"}}')
}
} catch (ParseException pe) {
return new JsonSlurper().parseText(' {"status":"error"}')
}
} else {
return new JsonSlurper().parseText(' {"status":"error"}')
}
See Scripting via Groovy for more information.
Validation using JavaScript
Like Groovy script, you can also define the validation code in JavaScript. Request and workflow variables are exposed along with the Webhook request object as wRequest (Refer WorkflowRequest class in GitHub). Validation script needs to return status (success/error) with other optional fields like workflow_variables and global_variables as JSON response.
Sample Javascript
function test() {
if (sys_amount == '7000' && wRequest.bot.languageCode == 'en') {
return {
'status': 'success',
'workflow_variables': {
'travel_year': '2019'
}
};
} else {
return {
'status': 'error'
};
}
}
test();
See Scripting via JavaScript for more information.
Response expected from Groovy and JavaScript Validation Scripts:
{
"messages": [...],
"render": "<WEBVIEW|BOT>",
"keyboard_state": "<ALPHA|NUM|NONE|HIDE|PWD>",
"status": "<success|error|2faPending|2faSuccess|2faFailure|pending|loginPending>",
"expected_entities": [],
"workflow_variables": {
"entity_1": "value_1",
"entity_2": "value_2"
},
"global_variables": {
"entity_3": "value_3",
"entity_4": "value_4"
}
}
Validation using Webhook
For complex cases, you can define a webhook to validate user input. Webhook defined will get a request with the event wf_validation or wf_u_validation. See Webhooks for more information.
Validation using Camel Route
Morfeus uses Apache Camel for integrations. You can define a camel route to do a complex validation. See Camel Routes for more information.
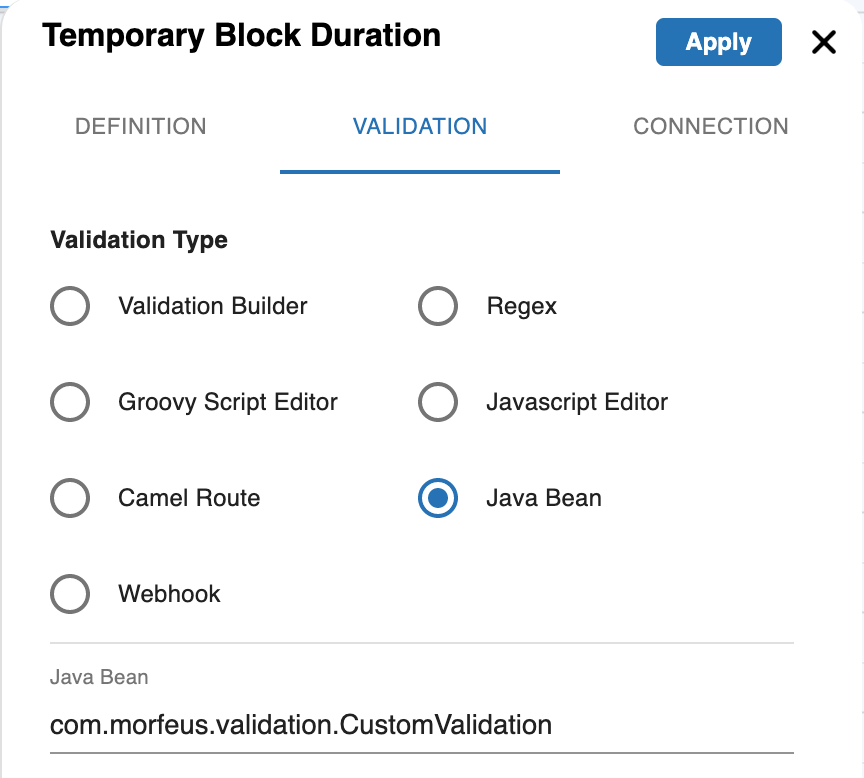
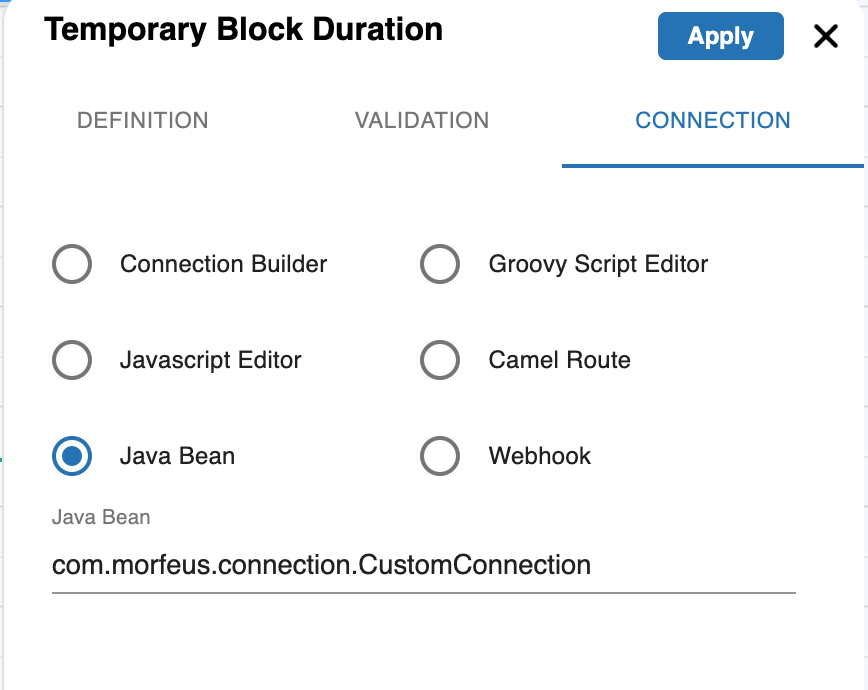
Validation using Java Bean
You can define a Java Bean to do custom validation. Your class is to implement interface com.morfeus.workflow.base.Validator. Your class to be packaged in a Jar file and to be added in the external jar folder of the application server. You can either create Spring bean of the class or Morfeus will manage the instance creation. In the workflow, you need to provide the class name with the package name.
public interface Validator {
ResponseMessageWrapper process(final CMM cmm, final WorkflowRequest workflowRequest);
}
Connections
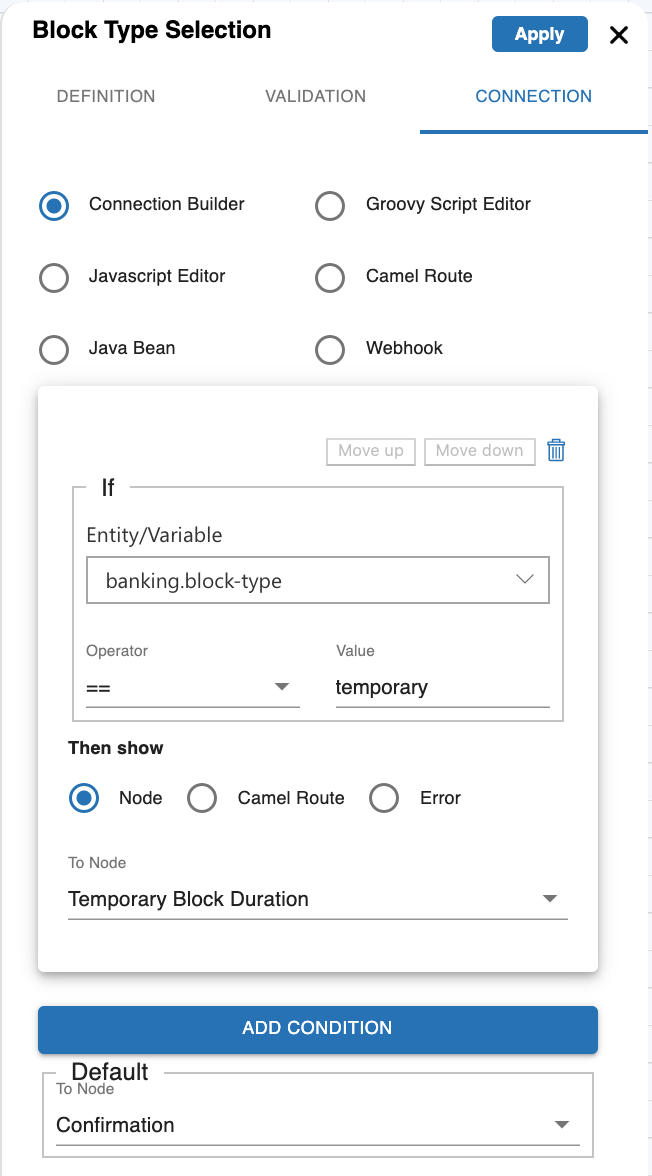
Based on the current input and other previous inputs, you can instruct what to do next. For that, you have the following options to define the connections between the nodes. For example, at node A you asked for user's age and now based on that you want to take a call whether to allow him to book the tickets or not. These kinds of rules you can define in the connections. When even you create a new node from an existing node, an entry is added in the connection of that node. You can define the conditions there, or if there is only a single connected node, it's automatically added as the default next node. To define these connections you have these options:
Connection Builder
Connection Builder is a GUI to define simple routing. It's the best option to go while defining a mockup of the flow or for simple use cases where routing is only based on entities or just a default routing. Whenever you create a new node from any existing node that new node entry is added to the parent node connection builder as default routing. If multiple nodes are added from a node, then you need to define the conditions to route to each node and can keep one as the default fallback node.
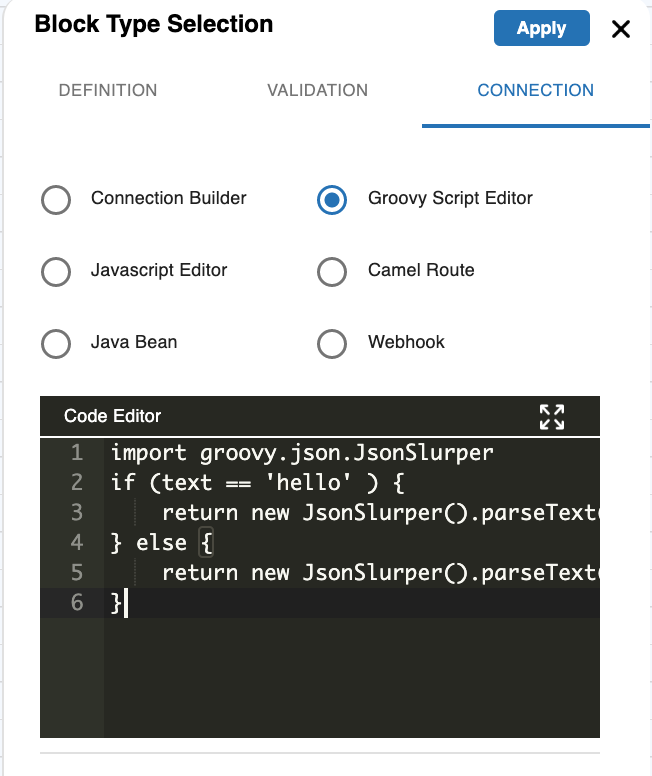
Groovy Script
You can use a Groovy script to define routing. The groovy script needs to return the response in JSON format. For example, as per below code snippet, if text is hello go to the node with id world else to the node with id error.
import groovy.json.JsonSlurper
if (text == 'hello' ) {
return new JsonSlurper().parseText('{"id":"world", "type": "node"}')
} else {
return new JsonSlurper().parseText('{"id":"error", "type": "node"}')
}
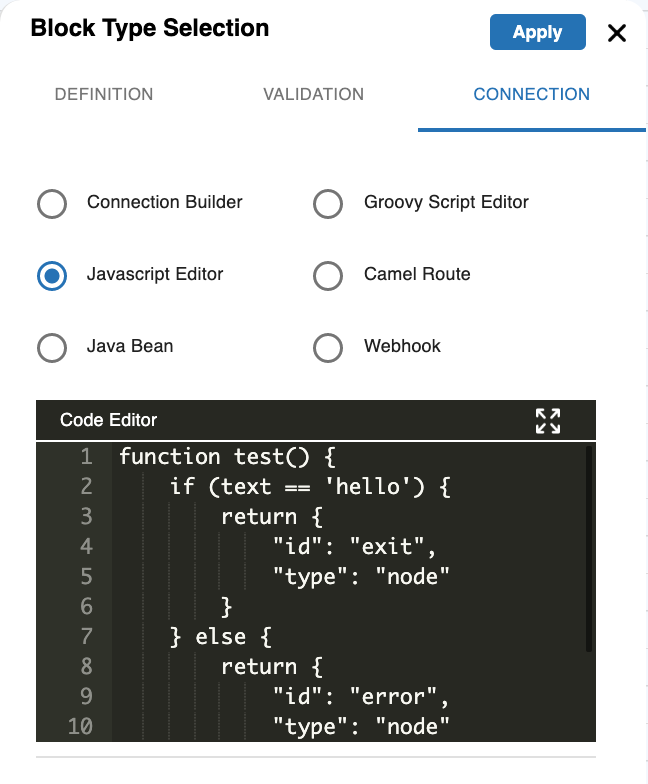
JavaScript
Similar to Groovy, routing can be achieved using Javascript function like:
function test() {
if (text == 'hello') {
return {
"id": "exit",
"type": "node"
}
} else {
return {
"id": "error",
"type": "node"
}
}
}
test();
Connection Webhook
You can define a webhook to define a dynamic routing. Webhook defined will get a request with the event wf_connection. See Webhooks for more information. The property of "webhook" as a tool to call API is useful here in case the connection needs extensive coding or in case the developer wants to exercise language discretion.
Routing through Camel Routes
Morfeus uses Apache Camel for integrations. You can define a camel route to do a complex routing. See Camel Routes for more information.
Routing through Java Beans
You can define a Java Bean to do custom routing. Your class is to implement interface com.morfeus.workflow.base.Connector. Your class to be packaged in a Jar file and to be added in the external jar folder of the application server. You can either create Spring bean of the class or Morfeus will manage the instance creation. In the workflow, you need to provide the class name with the package name.
public interface Connector {
public GoTo moveTo(final CMM cmm, final WorkflowRequest workflowRequest);
}
Scripting via JavaScript
Scripting via Groovy
Templates GUI
Button payload data to be in JSON format with data and intent. Data could be any JSON object.
For example:
{
"data": {
"flight-no": "AI381"
},
"intent": "txn-bookflight"
}
Features
- Workflow Cancellation
- Amend inputs
- Workflow Context
- Global Context
- Handling multiple inputs in a single statement
- Visualize flow
- Partial state save (Coming Soon)
- In step login
Debugging Workflows
~Coming Soon~
Workflow FAQs
Q. What can I do if I need to add a static prompt as well as a dynamic template.
A. You can use a combination of Send Message and Call Webhook to show a static text message followed by a dynamic template (or even text) sent from the API implementation. You can also use Call Webhook to do any number of text-template combinations.
Q. When is the text in update and error prompts in the "validation" tab of a node displayed?
A. Error prompt tells the user if a particular node validates the entity entered by the user as incorrect. Similarly, the update prompt is to let the user node if an older entity (the node that has already been executed) gets updated. Update Prompt gives the update message of the entity (node) that has been updated and not of the current node.
Q. What is the postback? What is the format to define that?
A. Postback is the request body that the server gets once the user clicks on any postback type button or quick reply. Morfeus expects it to be of JSON type with either 'intent' or 'type' and 'data'. For example, this is a valid postback:
{
"data": {
"flight-no": "AI381"
},
"intent": "txn-bookflight"
}
Q. How do I point a button to an FAQ?
A. You can create a postback type button with following postback data:
{
"data": {
"FAQ": "<<ANY TRAINED FAQ UTTERANCE>>"
},
"type": "MORE_FAQ"
}
Webhooks
Introduction
A webhook is nothing but an endpoint or an API that can be summoned to fulfill a particular task or in AI terminology, a particular intent. The primary motive to have a webhook as a mode of fulfillment is to call an API that can be written in any programming language and be hosted on a server and be accessible irrespective of the scope of the classes calling it.
We'll go through this feature to see how it can be leveraged to define a fulfillment for your intent.
Defining a Webhook
A webhook is reasonably easy to define. It just requires a URL and a secret key that is used to validate the requester of the API is accessed. Morfeus leverages the use of this feature to support vanilla fulfillment via webhooks and as part of other fulfillment as well, namely, Workflow. One can define a webhook as fulfillment for intent and in the same way a webhook can be called for a particular node's implementation within a workflow. Refer Workflows for a better understanding of workflow basics.
Webhook Signature
A Webhook signature has two components, namely,
Webhook Url : the URL of the webhook/API called to fulfill the intent.
Webhook Secret Key : a string value that is used to validate the requester by matching the values of the secret key in the signature and the one defined in the API. See Security for more information on how to secure your webhook using a security key.
To create a fulfillment via webhook for a particular intent you can choose Call Webhook option.
Conversational Workflow Framework
Please refer to the article on workflow for the detailed understanding of dialog flow management.
Other than acting as a method of fulfillment for an intent all by itself, webhook can also be leveraged to support certain parts of steps within a workflow. As we know that workflow is essentially a sequential and logical implementation of steps (nodes), it might be required to have multiple logical checks to be made to decide which step (node) to call next. It may not always be the best idea to perform these tasks within the static scripts within a node, or worse in multiple nodes. This is where webhooks come into the picture.
You can define a webhook to implement prompt, validation or connections of a node in a workflow. The definition/signature of the webhook is the same as above, i.e., a URL and a secret key, just the purpose changes.
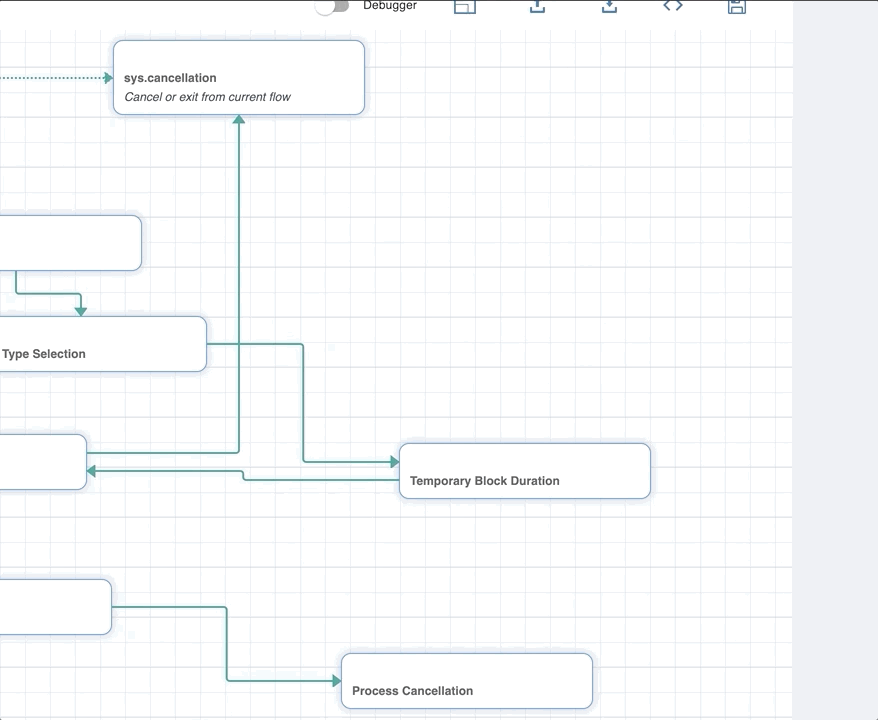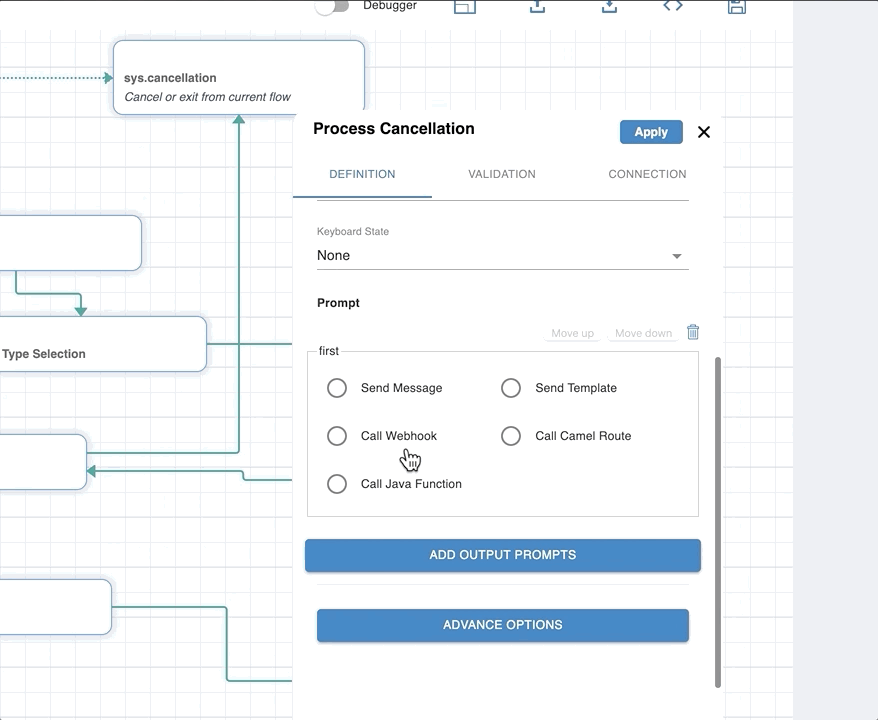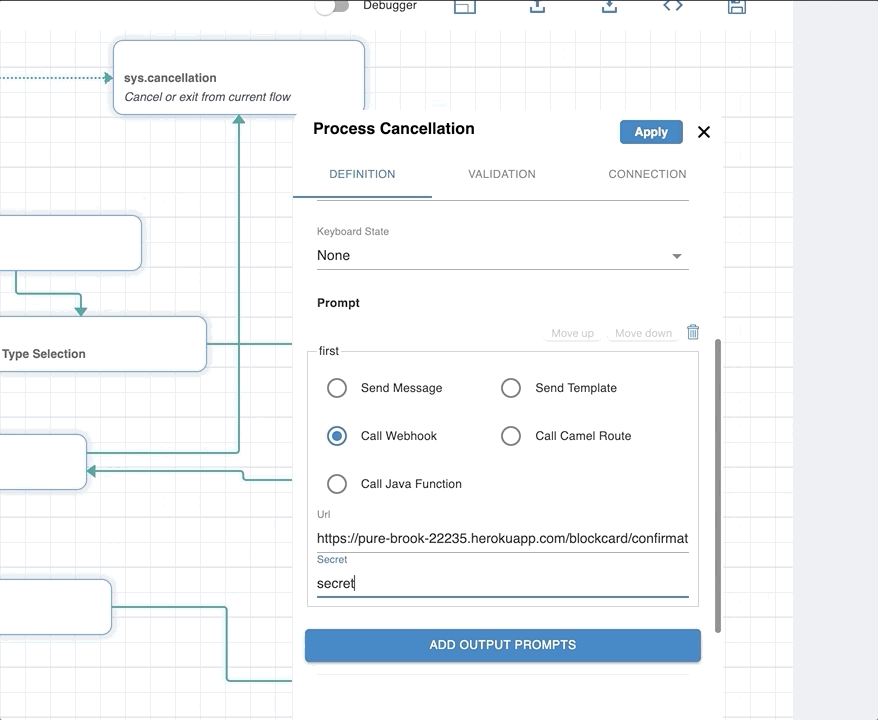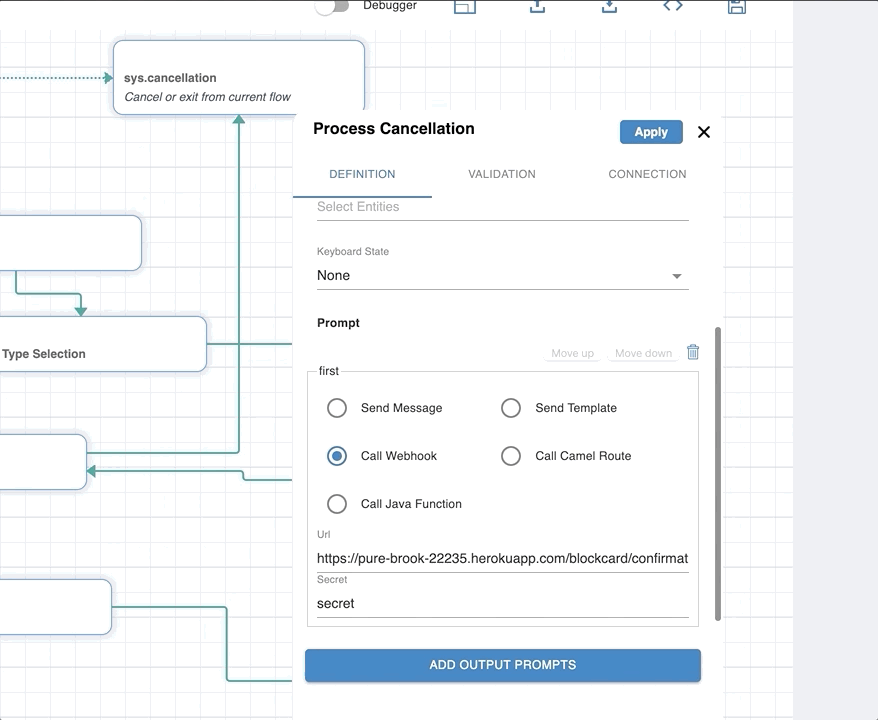
Events
All webhook events to have a similar request body. Just for the workflow events request to have an extra workflow object. The available webhook events are listed below.
| Table 4 Events | ||
| Event | Description | |
|---|---|---|
| fulfilment | For any message if handled by global or the intent based webhook. | |
| wf_validation | Inside workflow execution for user input validation. | |
| wf_u_validation | Inside workflow execution for validation of updated value. | |
| wf_connection | Inside workflow execution for connection. | |
| wf_prompt | Inside workflow execution for prompt. | |
Webhook Request
Your webhook to receive a POST request from Morfeus. For each message from a user, this webhook will be called, depending on the webhook is configured for across bot or per intent. This request format is chosen to simplify the response parsing on the service side to handle multiple channels.
A request to comprise of the following fields to give you details about the bot, user profile, user request, and NLP. For text requests, request the body to have all the enabled fields for NLP, for postback requests you may get a few of them.
Generic Webhook Request Format
{
"id": "mid.ql391eni",
"event": "wf_validation",
"user": {
"id": "11229",
"profile": {}
},
"bot": {
"id": "1874",
"channel_type": "W",
"channel_id": "1874w20420077206",
"developer_mode": true,
"sync": true
},
"request": {
"type": "text",
"text": "mumbai"
},
"nlp": {
"version": "v1",
"data": {
"processedMessage": "mumbai",
"intent": {
"name": "txn-bookflight",
"confidence": 100.0
},
"entities": {
"intentModifier": [{
"name": "intentModifier",
"value": null,
"modifiers": []
}],
"source": [{
"name": "source",
"value": "mumbai",
"modifiers": null
}]
},
"debug": [{
"faq-subtopic-confidence": 0.0,
"faq-topic-confidence": 0.0
}],
"semantics": [{
"sentence-type": "instruction",
"event-tense": "present",
"semantic-parse": "location:DESCRIPTION[]"
}]
}
},
"workflow": {
"additionalParams": {
},
"workflowVariables": {
"modifier_intentModifier": "",
"modifier_destination": ""
},
"globalVariables": null,
"requestVariables": {
"intentModifier": "null",
"source": "mumbai"
},
"nodeId": "Source",
"workflowId": "bf9f3713-7921-4927-8a40-5876b1012543"
}
}
Request Body
| Table 5 Request Body | ||
| Property | Type | Description |
|---|---|---|
| user | Object | User object. User details acquired from that particular channel |
| time | String | Timestamp of the request |
| request | Object | Request object. User Request Details |
| nlp | Object | NLP object. Natural Language Processing information about the request |
| id | String | Unique ID for each request |
| event | String | Event Type |
| bot | Object | Bot object. Bot details |
| workflow | Object | Workflow object. Only for requests made from workflow. |
User Profile
| Table 6 User Profile | ||
| Property | Type | Description |
|---|---|---|
| id | String | Channel User ID |
| profile | Object | Profile information acquired from the Channel |
Bot Details
| Table 7 Bot Details | ||
| Property | Type | Description |
|---|---|---|
| id | String | Triniti AI Bot ID |
| channel_type | String | Channel type |
| channel_id | String | Channel ID for the Bot |
| developer_mode | Boolean | Developer or Live mode |
| language_code | String | Bot language code |
| sync | Boolean | Channel is sync or async |
Natural Language Processing
| Table 8 Natural Language Processing | ||
| Property | Type | Description |
|---|---|---|
| version | String | Triniti API version |
| body | Object | NLP body fields depends on Triniti API version |
Workflow Object
| Table 9 Workflow Object | ||
| Property | Type | Description |
|---|---|---|
| workflowId | String | Unique ID for workflow |
| nodeId | String | Unique ID for workflow node |
| requestVariables | Object | Local request variables |
| workflowVariables | Object | Variables persisted across workflow |
| globalVariables | Object | Variables persisted across session |
| additionalParams | Object | Some additional data |
You can use Webhook Java library to parse the request.
Webhook Response
Webhook's response has most of the generic components, but some are specific to its implementation within the workflow.
Following is the expected webhook response structure.
Generic Webhook Response Format
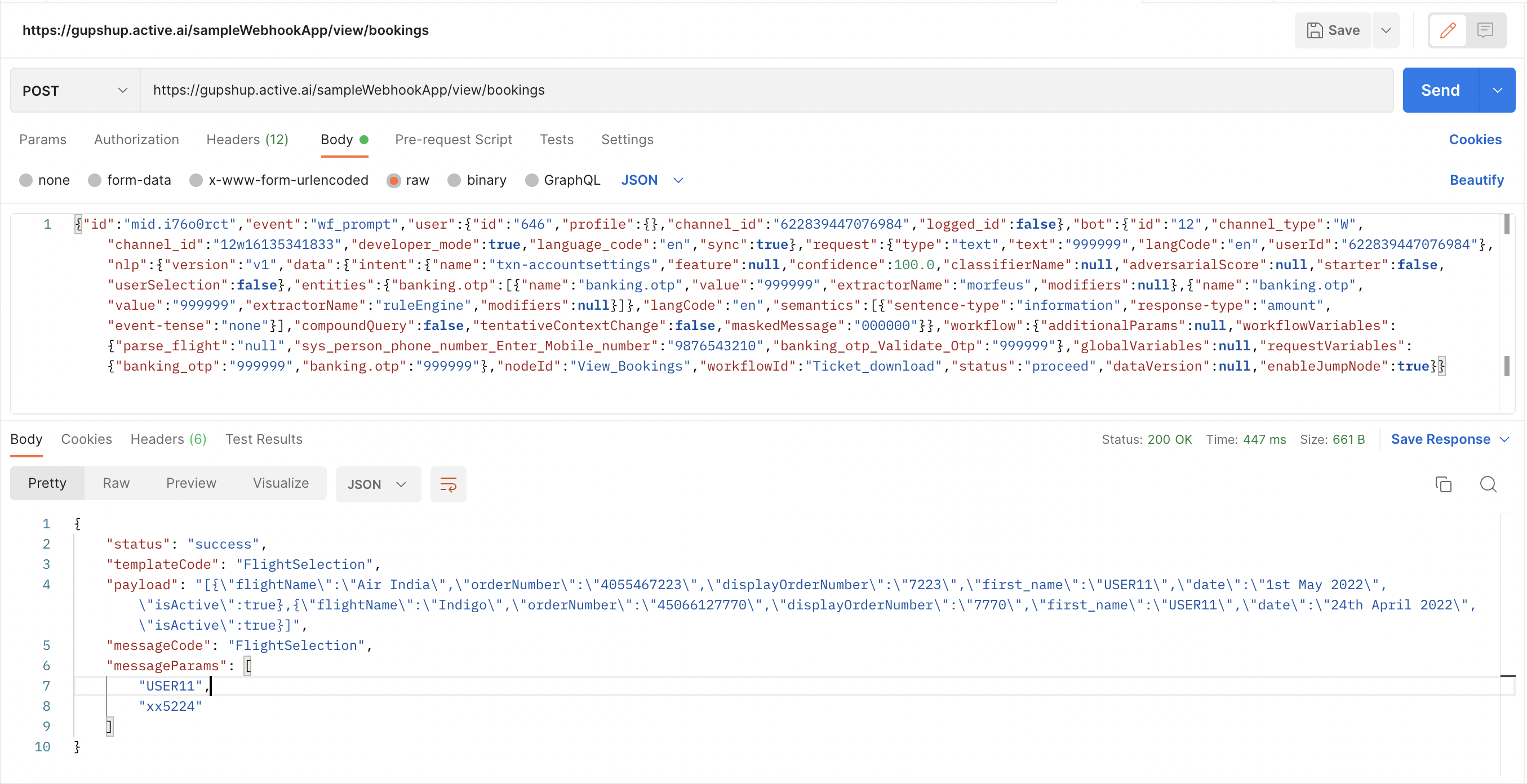
Forming Webhook Response by passing templateCode payload, messageCode & message params :
{
"status": "success",
"templateCode": "FlightSelection",
"payload": "[{\"flightName\":\"Air India\",\"orderNumber\":\"4055467223\",
\"displayOrderNumber\":\"7223\",\"first_name\":\"USER11\",
\"date\":\"1st May 2022\",\"isActive\":true},
{\"flightName\":\"Indigo\",\"orderNumber\":\"45066127770\",
\"displayOrderNumber\":\"7770\",\"first_name\":\"USER11\",
\"date\":\"24th April 2022\",\"isActive\":true}]",
"messageCode": "FlightSelection",
"messageParams": [
"USER11",
"xx5224"
]
}
You can use the Webhook Java library to form the response.
- It has the provision to pass template code and payload from the webhook response
- Template with the passed template code to be created in the Template Editor or Manage Templates in Admin.
- Based on the template type payload to be passed as either a
- Map
- A List of Map: List
- Map
- A message with the passed message code to be created in the Manage Messages in Admin
- Dynamic values to be populated in the message value can be passed in messageParams which is a String array.
Forming Webhook Response by passing template or message object :
{
"messages": [{
"type": "text",
"content": "<text_message>",
"quick_replies": [{
"type": "text",
"title": "Search",
"payload": "<POSTBACK_PAYLOAD>",
"image_url": "http://example.com/img/red.png"
}, {
"type": "location"
}]
}, {
"type": "list",
"content": {
"list": [{
"title": "",
"subtitle": "",
"image": "",
"buttons": [{
"title": "",
"type": "<postback|weburl|>",
"webview_type": "<COMPACT,TALL,FULL>",
"auth_required": "",
"life": "",
"payload": "",
"postback": "",
"intent": "",
"extra_payload" :"",
"message": ""
}]
}],
"buttons": []
},
"quick_replies": []
}, {
"type": "button",
"content": {
"title": "",
"buttons": []
},
"quick_replies": []
}, {
"type": "carousel",
"content": [{
"title": "",
"subtitle": "",
"image": "",
"buttons": []
}],
"quick_replies": []
}, {
"type": "image",
"content": "",
"quick_replies": []
}, {
"type": "video",
"content": "",
"quick_replies": []
}, {
"type": "custom",
"content": {}
}],
"render": "<WEBVIEW|BOT>",
"keyboard_state": "<ALPHA|NUM|NONE|HIDE|PWD>",
"status": "<SUCCESS|FAILED|TFA_PENDING|TFA_SUCCESS|TFA_FAILURE|PENDING|LOGIN_PENDING>",
"expected_entities": [],
"extra_data": [],
"audit": {
"sub_intent": "",
"step": "",
"transaction_id": "",
"transaction_type": ""
}
}
You can use Webhook Java library to form the response.
It has provision to accept responses of multiple types, namely :
- Text: a simple text response
- List: a vertical list-like-template showing list of cards/pictures.
- Button: a button that on being clicked sends back a response to the bot.
- Carousel: a horizontal-list-like-template showing a scrollable list of cards/pictures.
- Image: a simple image
- Video: a simple video
Find below the definition of all these types of templates :
Templates
Model Template definitions
1. quickReplyTextTemplate
Sample :
{
"button":["Select"],"title":"XXXX 5100"
}
2. imageTemplate
Sample :
{
"image":"imgs/card.png"
}
3. buttonTemplate
Sample :
{
"buttons" : [ {
"title" : "yes"
} ]
}
4. carouselTemplate
Sample :
[
{
"buttons" : [ {
"title" : "yes"
}
],
"image" : "https://beebom-redkapmedia.netdna-ssl.com/wp-content/uploads/2016/01/Reverse-Image-Search-Engines-Apps-And-Its-Uses-2016.jpg",
"title" : "head",
"subtitle" : "subtitle"
}
]
5. listTemplate
Sample :
{
"list": [
{
"image": "imgs/card.png",
"buttons": [
"button"
],
"subTitle": "XXXX 5100",
"title": "VISA"
},
{
"image": "imgs/card.png",
"buttons": [
"button"
],
"subTitle": "XXXX 5122",
"title": "VISA"
},
{
"image": "imgs/card.png",
"buttons": [
"button"
],
"subTitle": "XXXX 5133",
"title": "VISA"
}
]
}
6. videoTemplate
Sample :
{
"video": "https://www.w3schools.com/html/mov_bbb.mp4"
}
7. custom
This type can have user-defined JSON payload to render a user-defined template. The above templates are what is provided to the user by Morfeus, but the user is free to define his/her own templates/response types and populate them from his/her API.
Other components of response :
- render: tell where to render the response, as part of webview (a new dialog box with text fields coving the entire chat space) or generally as part of the chat window (like any other chat inside the window).
- keyboard_state: type of keyboard for the response (ALPHA|NUM|NONE|HIDE|PWD)
- status: shows the status of the API call (success/failure).
- expected_entities: is a list of a string with all the entities that the intent is expecting to be picked up by the AI engine.
- extra_data: extra data that one wants to be the part of the response.
- audit: step ID. defined for auditing purposes.
As part of Workflow, Webhook responses have some additional fields, namely :
- goto: if the user wants to branch to another step after the logical execution of the current step, this feature can be used for the backend to understand which step it needs to execute next.
- gotoType: pass the type of goto you are defining (e.g., to branch to another step, type = "node")
- gotoLinkedType: tell the backend if the user wants to have some linking to his logical decision outcome. It is used for back-editing. If the user wants to revisit a particular step to get the entity filled with another value, this feature can be used (e.g., gotoLinkedType = "backlink")
- expected_entities: this feature we've discussed above as part of webhook fulfillment but this is also handy in case of workflow as this can tell the server that a particular entity needs to be filled before crossing the current step. It is particularly helpful in case of validation where in case of failure one can define the entity name so that the server makes it a point to get that entity populated by the user before moving on.
Security
The HTTP request contain an X-Hub-Signature header which contains the SHA1 signature of the request payload, using the app secret as the key, and prefixed with sha1=. Your webhook endpoint can verify this signature to validate the integrity and origin of the payload.
Please note that the calculation is made on the escaped Unicode version of the payload, with lower case hex digits. For example, the string äöå will be escaped to \u00e4\u00f6\u00e5. The calculation also escapes / to \/, < to \u003C, % to \u0025 and @ to \u0040. If you calculate against the decoded bytes, you will end up with a different signature.
Java sample code available at GitHub.
Spring Beans
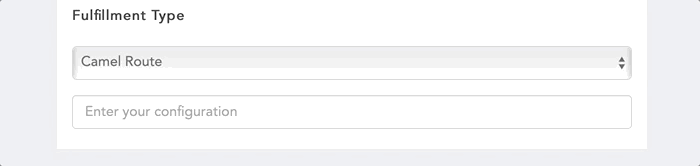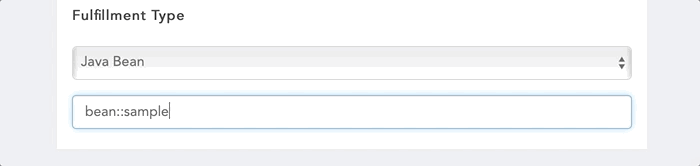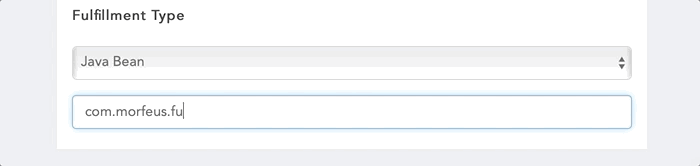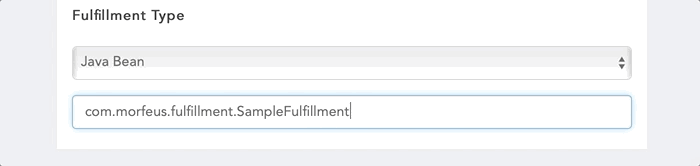
You can define a Java Bean to define a fulfillment. Your class is to implement interface com.morfeus.common.fulfillment.MorfeusFulfillmentBean. Your class to be packaged in a Jar file and to be added in the external jar folder of the application server. You can either create Spring bean of the class or Morfeus will manage the instance creation. If you have created Spring bean, provide bean name prefixed with 'bean::' else you need to provide the full class name with the package name.
Check Sample Fulfilment Code on GitHub
Interface to define fulfillment bean:
@FunctionalInterface
public interface MorfeusFulfillmentBean {
public ResponseMessageWrapper execute(CMM cmm) throws MorfeusFulfillmentException;
}
Camel Routes
~Coming Soon~
Paginated Data
Technical Diagram
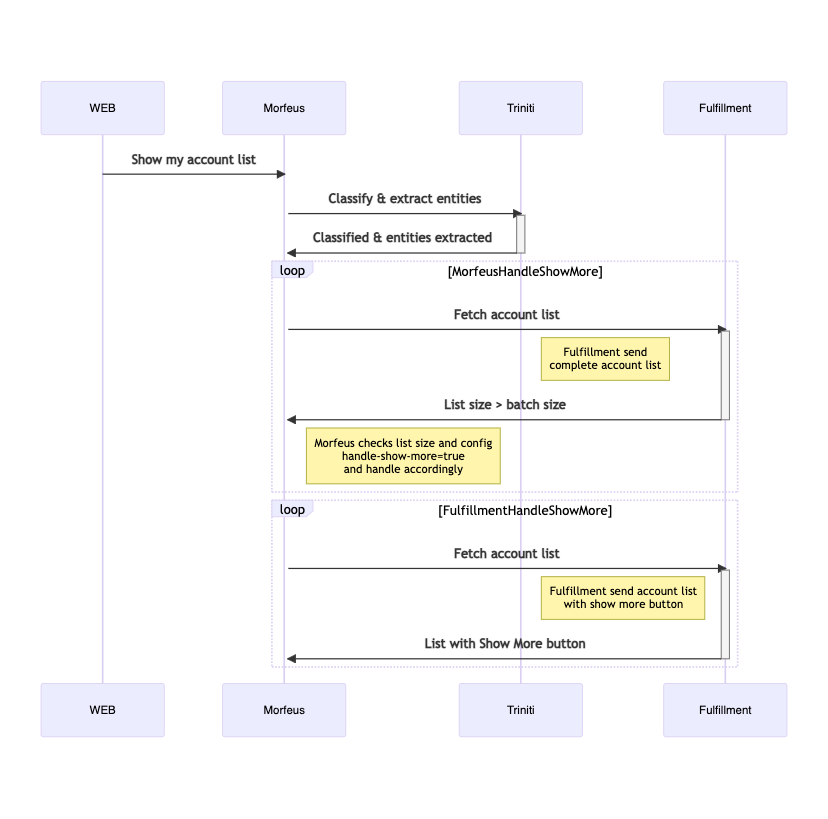
Show more feature is further divided into two different components:
- Show Next: Show next allows you to partition the LIST into batch sizes, followed by a show next button
- To use this feature make sure to have entered the batch size in the manage channel → edit channel.
- Once batch size is set you will need to send LIST template with elements more the the given batch size.
- Show more feature will work with only LIST template.
- With addition to above configuration you will need to send additional property in cmm to inform morfeus that show more button has to be enabled. The property to be sent is **“
show_more“:”more”. If you dont have access to CMM additional paramters and if using any other fuilfillment then you can send same property in ResponseMessageWrapper “response“. - Title of the button can be configured by setting the bot message with Message code “
SHOW_MORE_TITLE“. - Show All: Show all allows you to make 1st partition of LIST as per the batch size , followed by a show all button, on clicking which will show all the elements of the LIST.
- To use this feature make sure to have entered the batch size in the manage channel → edit channel
- Show all feature will work with only LIST template.
- With addition to above configuration you will need to send additional property in cmm to inform morfeus that show more button has to be enabled. The property to be sent is “
show_more“:”all”. If you dont have access to CMM additional paramters and if using any other fuilfillment then you can send same property in ResponseMessageWrapper “response“. - Title of the button can be configured by setting the bot message with Message code “
SHOW_ALL_TITLE“.
Show more/Show all is a channel specific feature, batch size in each channel config will play a role to enable/disable this feature.
Template Editor
Template Editor gives you a way to create a rich media in-conversations in the bot which is not the usual text messages - per channel per language. Templates can be used for many purposes such as displaying the account balance, doing a transfer, showing the bills to paid and many more. Also helps in building multi channel responses.
Text template
Text template is a simple message which includes a text which supports rich text format.
How to create

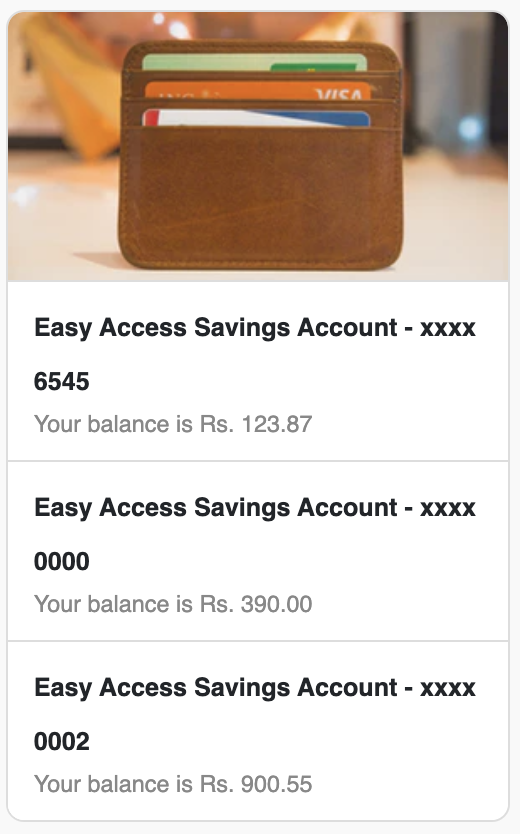
List template
List template is a list of 1 or more messages with a button at each item, Each item in the list includes title, subtitle, image and buttons.
How to create

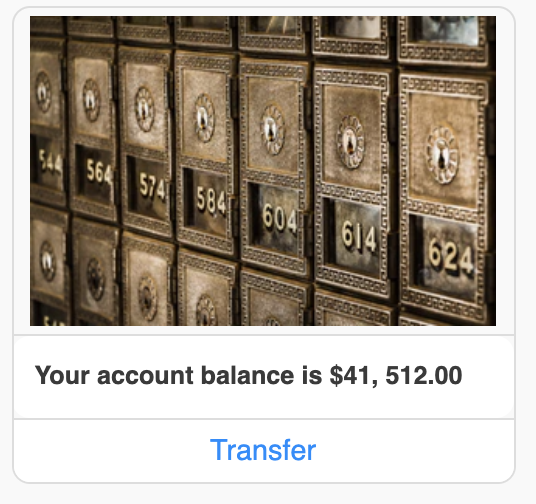
Card template
Card template is a structured message which includes title, subtitle, image and call-to-action buttons. You can create 'n' number of call-to-action buttons.
How to create

Button template
Button template send a message which includes text and buttons. This templates is useful when there a multiple options to choose.
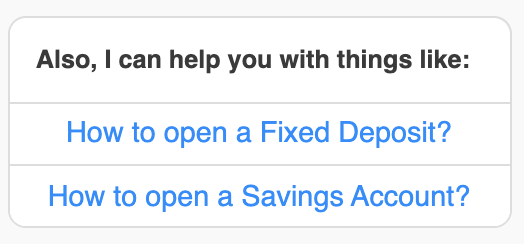
How to create

Image template

How to create

Video template

How to create

Image template & Video template is a message which support the media.
Quick replies
Quick replies is used to a list of quick replies in the chatbot. This usually comes in the footer section of the chatbot which are stagnant.
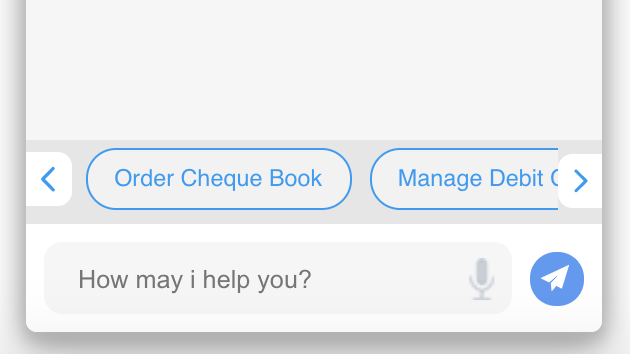
How to create

Multi Channel
Create your messages on all the major messaging channels. We support Messenger, Skype, Amazon Alexa and many more.
Screens
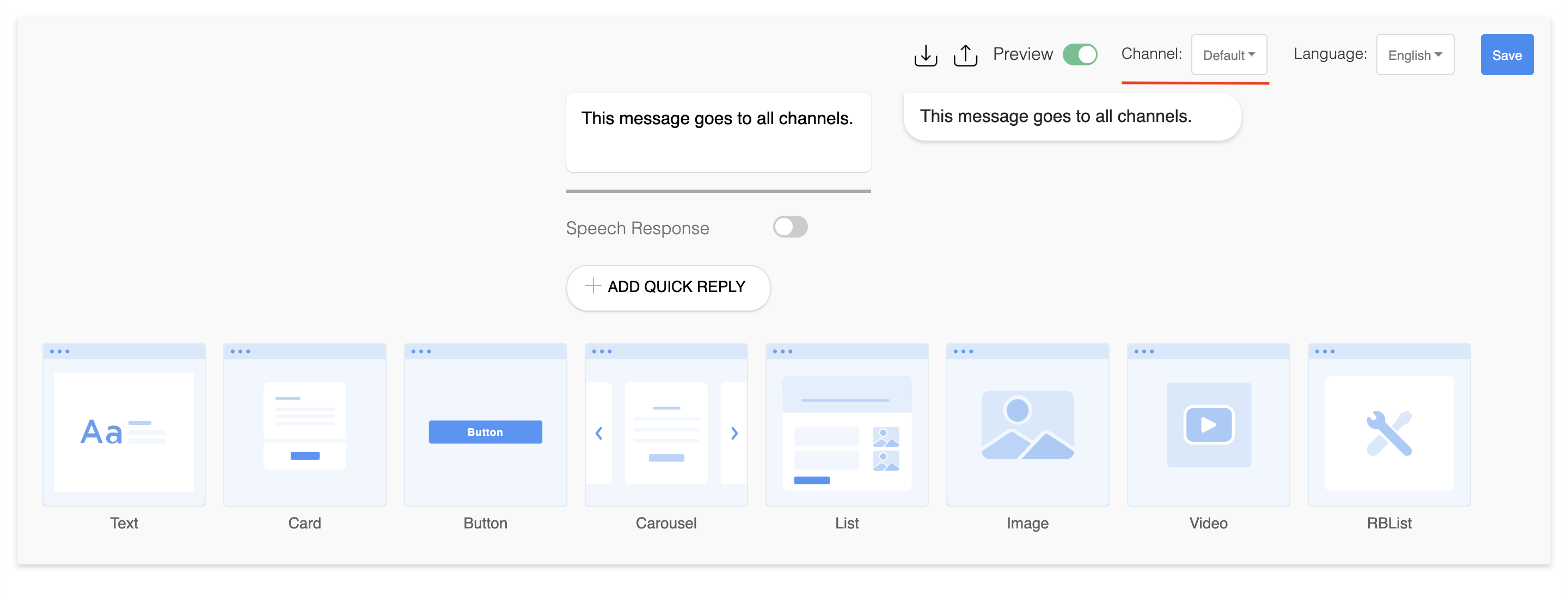
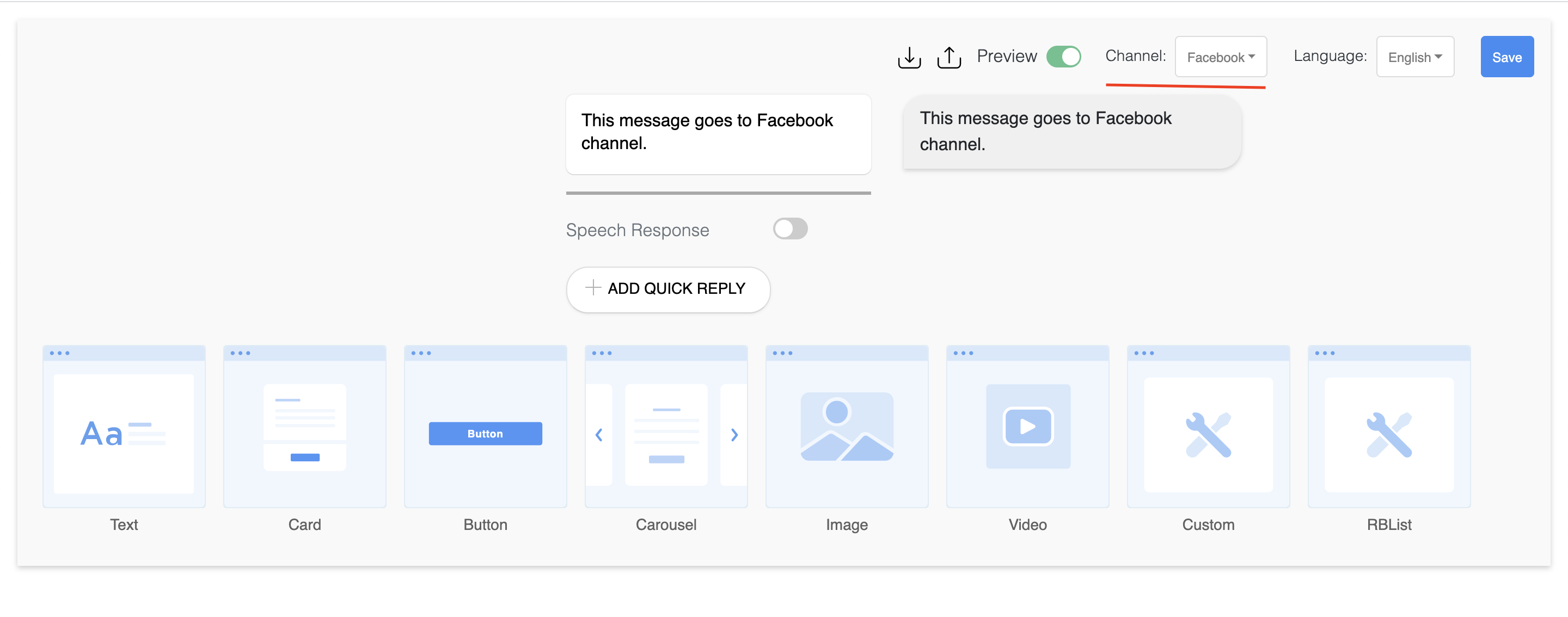
How to create a multi channel response

Multi Language
Create your messages for many languages like English, Hindi, Spanish, Thai, Japnese, Chinese, Arabic & Singalese.
Screens
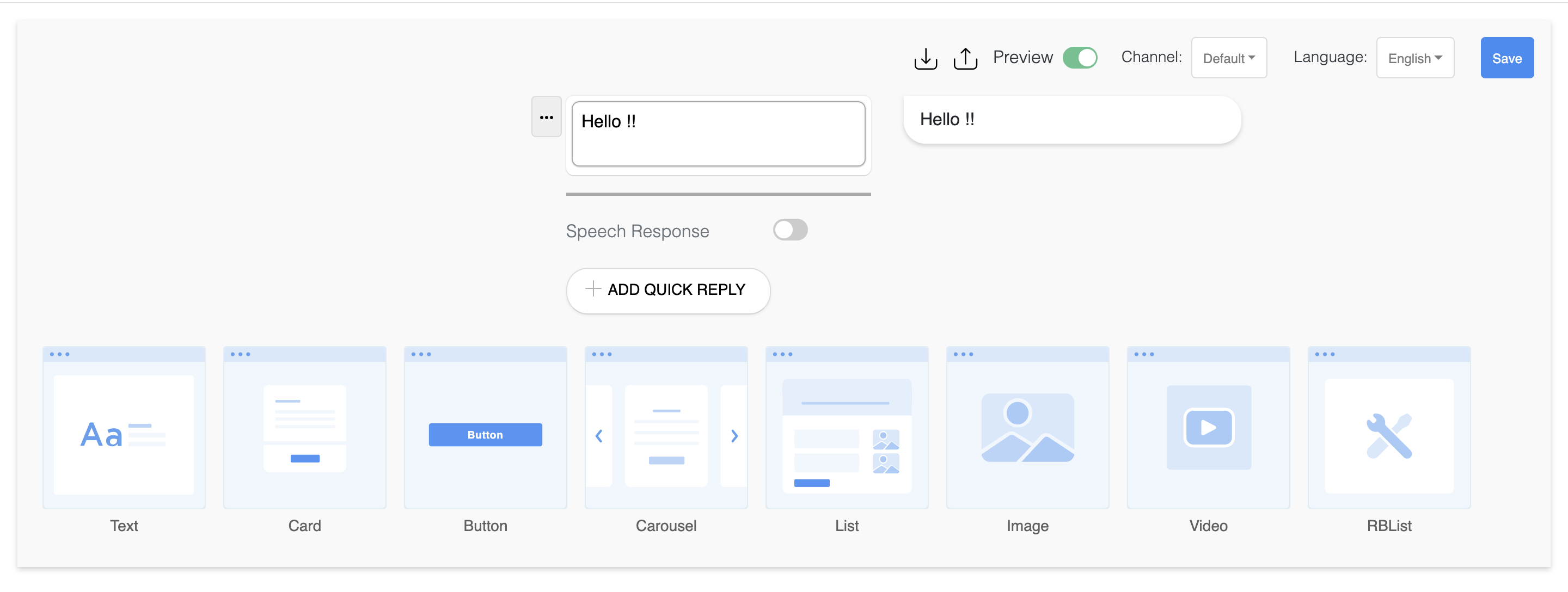
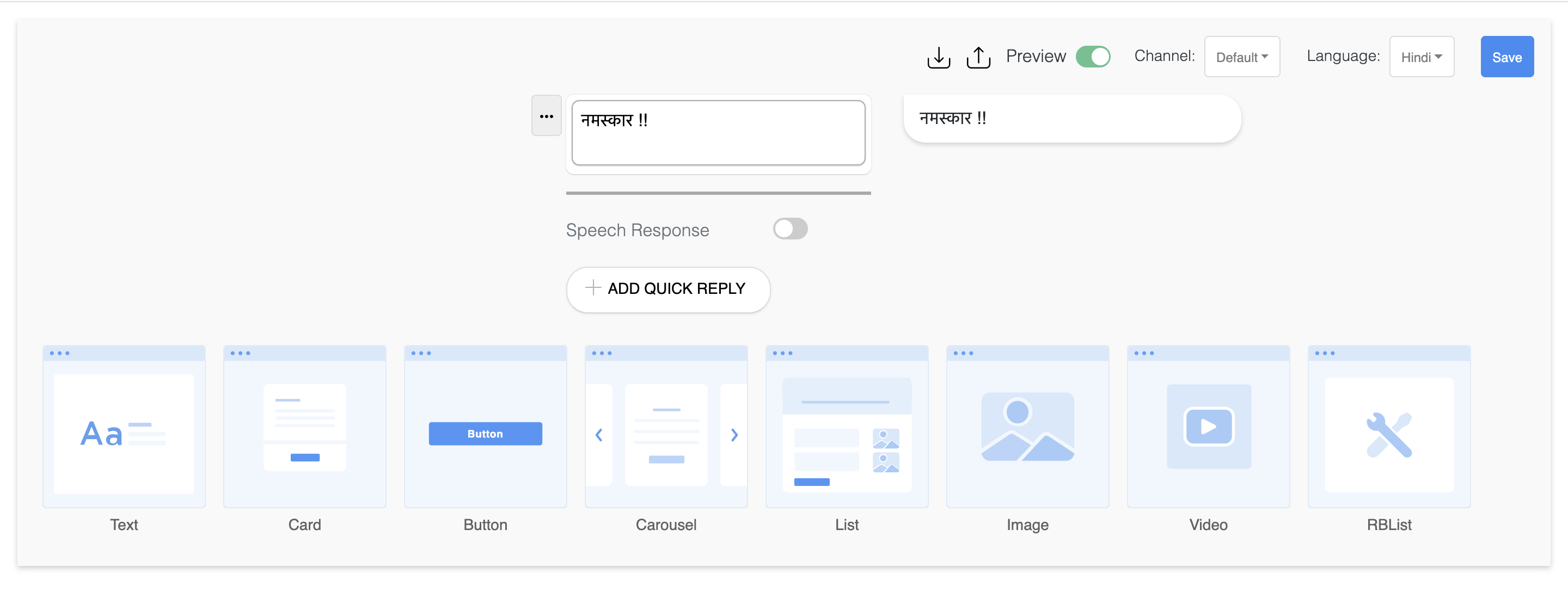
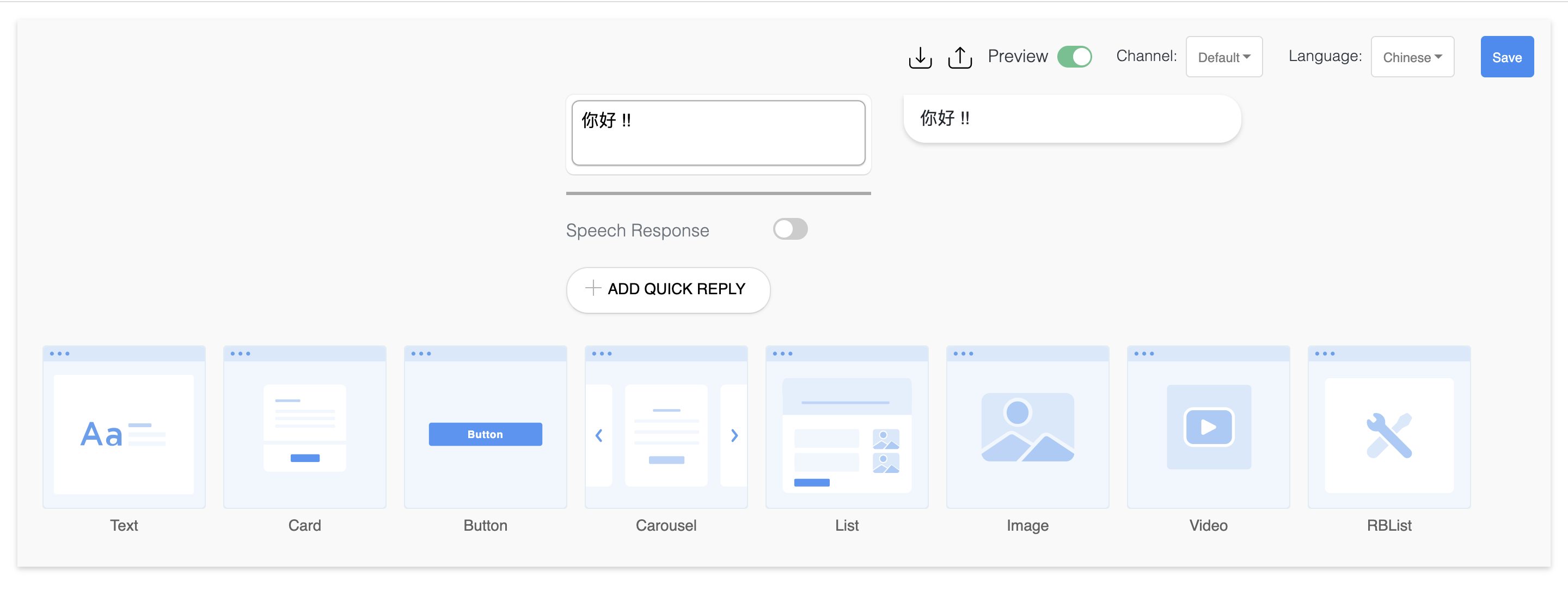
How to create a multi language response

Custom template
Custom template is a way to create a template which can be customized with your specifications. Custom template is currently supported by our web channel, In custom template you can write your own JavaScript, HTML & CSS which will be rendered in the bot.
NOTE: jQuery is enabled in the bot
How to create a custom template
In the below example, Creating a custom list template is shown.
- Both template name and template markup content is required to save the custom template.
- After saving the template, you can find the created template in the template selection list.

Custom template comprimises of handlebars templating structure, it also supports any JavaScript, any CSS along with it.
The processing and parsing of the handlebars data is process by morfeus, The bot just renders the UI of template
Dynamic template
Dynamic template is a way to create a template for dynamic data, this is used for a scenario like Showing Accounts Balance, Showing List of Credit Cards, Showing list of payees
How to create a dynamic list template


Failover to Human Agents
Overview of Fallback to agent
- Fallback to agent is basically a failure scenario which is triggered due to 3 reasons :
- After a specified number of failed AI conversations between the user and the bot.
- On negative sentimental analysis.
- If the user enters a text value, configured to directly trigger manual chat.
Setup of Fallback to agent
- For this failure scenario to work these configurations should be checked :-
- Enable the rule "Enable/disable Customer Support Fallback", which is there in Configure Workspace --> Manage Rules --> under Manual Chat tab.
- Then based on the rule "Enable fallback on failed AI conversations" which is also there in the above mentioned location, this rule Specifies the number of failed AI conversations before the system falls back to a customer support agent. On the basis of the mentioned no for failed ai conversation fallback to Human Agent is triggered.
- Also enable the rule "Enable fallback on sentimental analysis" which is also in the same location.
We support two agent providers :
- LiveChat
- Zendesk
Trigger fallback to LiveChat, there are some configurations which are needed which are as follows:
- First go to MANAGE HOOKS and check if the following hooks consists of a route which is calling the mentioned bean:
- fallback_initiate hook --> bean:liveChatResponseHandlerv3
- fallback_send_message --> bean:liveChatResponseHandlerv3
- fallback_close --> bean:liveChatResponseHandlerv3
- fallback_agent_request_transform --> bean:agentRequestTransformerv3
- Now go to To make your own LiveChat Application.
- Create an account then you will be redirected to this page

- Click on Go to Apps

Now here select "create new app". Now give your app a name and for app template select "Server-side web hook app".
- Now you will see this page


From here copy the "Client Id", "Client Secret","License" and paste the "Client Id" in your admin → Configure Workspace → Manage Rules → and then under manual chat tab paste this value in Agents client id. Paste "Client Secret" in your admin → Configure Workspace → Manage Rules → and then under manual chat tab paste this value in Manual Chat Agent Provider API Key. Paste "License" in your admin → Configure Workspace → Manage Rules → and then under manual chat tab paste this value in Agent Chat License Key.


- Now go to your admin and then click on "Active.Ai" which will be on top extreme left, after clicking that click on "Settings" → under general tab --. got to "Domain name of the Morfeus Admin platform with Protocol"
rule and their check if the domain is correct and if it is empty then provide the correct domain with context where your admin instance is present for e.g "localhost:8443/"
Then go to → Configure Workspace → Manage Rules → and then under manual chat tab → "Mode of Manual Chat Agents request to morfeus" rule and select "Webhook". Then go to → Configure Workspace → Manage Rules → and then under manual chat tab →Agent chat fallback url rule and there provide the URL to access morfeus for the agent chat on fallback I.e → https://localhost:8443/morfeus/v1/chatagent/callback
Now go to Configure Workspace → Manage Rules → and then under manual chat tab → "Select the agent provider for manual chat fallback" select LiveChat V3 and then on selecting livechat. Do not click on the button before doing the next step → you will see a box with two urls and three scopes you need to add those urls in your livechat app in authorization tab for whitelisting these api's and the three scopes.


For urls to be whitelisted

For scopes to be added:

- After adding the urls and scopes then click on the button to get the refresh token.After clicking you will get a refresh token in rule "Agents refresh token". Once you get the refresh token --> login to the account which you made using this link → https://accounts.livechatinc.com/?client_id=bb9e5b2f1ab480e4a715977b7b1b4279&response_type=token&redirect_uri=https%3A%2F%2Fmy.livechatinc.com&state=%7B%22redirectTo%22%3A%22keep-on-chatting-with-customers%22%7D. Now your livechat configuration is done and fallback to human agent(using livechat) will be triggered successfully.
Supported Fallback Service Provider
| Table 10 Supported Fallback Service Provider | ||
| Provider | Out-of-box Support | Customization |
|---|---|---|
| LiveChat | Yes | Yes |
| Zendesk | Yes | Yes |
| Freshchat | Yes | Yes |
| Talisma | No | Yes |
| Genesys | No | Yes |
Intercepting and Handling Failures
There could be some failure scenarios which we need to configure how we want the bot to respond. Like utterance is not classified or negative sentiment is perceived etc. Below is the list of all failure scenarios and steps to handle them gracefully.
1) Utterance not able to classify
2) Ambiguity in utterance classification
3) Profanity
4) Negative sentiment
5) Intent fulfilment not defined
6) Smalltalk no response
7) FAQ no response
8) General error
9) Fallback to agent
Utterance not able to classify
Triniti return intents with a confidence score. The message is considered as unclassified, ff the score is below the configured minimum threshold. There are few ways to handle those utterances:
1) If KnowlegdeGraph is enabled, it can try to probe for further information. Like if the user asks "Apply", it might be unclassified. If KnowlegdeGraph is enabled, based on the ontology configured, it might probe for "Apply for account" or "Apply for credit card".
2) If some product exists in the utterance and bot rule 'Web search for unclassified utterances' is enabled, unclassified utterances go to FAQ fallback.
3) You can customize the behaviour by defining your implementation for the intent named 'not-able-to-classify'.
4) Default is to return message configured using message code 'not_able_to_classify' if none of the above is configured.
5) If fallback to the agent is configured, after the set number of failures, the bot can fallback to an agent.
Ambiguity in utterance classification
Messages with classifier confidence score between minimum and maximum, are categorized as ambiguous statements.
1) If KnowlegdeGraph is enabled, it can try to probe for further information. Like if the user asks "Apply cancel", it might be ambiguous. If KnowlegdeGraph is enabled, based on the ontology configured, it might probe for "Do you want to apply for an account?" or "Do you want to cancel an account?".
2) Return a 'GiveSuggestionTemplate' named template. The payload for the template would include either the primary utterances for the intents or, you can define custom messages by setting message for message code using format, "SUGGEST_{INTENT_NAME_IN_CAPS}_{ANY_PRODUCTS_EXTRACTED}".
Profanity
Any profanity words are replaced with the phrase "Profanity" and treated as Smalltalk. To define response for it add a Smalltalk for utterance "Profanity".
Negative Sentiment
Triniti can gauge the sentiment of the user and provides a score to depict the negative and positive emotion. You can configure the bot rule "Negative sentiment threshold" in range on 0 to 1, the recommended value 0.5. Low value could lead to more false positives. Following are the ways you can handle the negative sentiment of the user.
1) If the user is in between a transaction and bot perceives a negative emotion, we recommend to show an apology message and continue with the transaction. To configure the apology message, use the "APOLOGY_MESSAGE" message code, or the system would use the default message "I am sorry about your experience.".
2) If not in a transaction and intent is not FAQ, render template "NegativeSentimentTemplate". Using this template you can also configure to fallback to an agent.
Intent fulfilment not defined
Intent fulfilment not defined is very unlikely in production that you haven't configured a fulfilment for an intent. Though if that happens and a bot rule 'Handle Unmapped/Unsupported Intents as a FAQs' is enabled, the system will process that user utterance as FAQ. And in case you don't want to process those messages as an FAQ, you can configure a message using message code 'unmapped_intent'.
Smalltalk no response
In cases where utterances are classified as a Smalltalk, but the confidence of the response is below the threshold or because of some reason response is not present, you can customize the behaviour by defining your implementation for the intent named 'not-able-to-classify'. Else "srm_no_result" message is returned. The Smalltalk threshold is defined using bot rule "Min Smalltalk Confidence".
FAQ no response
FAQs are one of the essential aspects of the conversation agent, hence requires the most attention. Many a time utterance is rightly classified as FAQ, but response confidence is below the threshold or grain type of user utterance, and top candidate utterance doesn't match. The FAQ threshold is defined using bot rule "Min FAQ Confidence". Grain type verification can be configured using "Enable Grain Type Verification" bot rule. There are many fallback mechanisms for the unanswered FAQs.
1) If "Web search for FAQ" rule is enabled:
- if KnowledgeGraph is enabled and "Enable Knowledge Graph Lookup for FAQ Fallback" is enabled, handle it using to KnowledgeGraph probing.
- can define your custom implementation by enabling "Enable External FAQ Fallback" rule and defining "direct:retail.banking.search.result" route.
- if "Enable Elastic Search as Fallback" rule is enabled, the system will hit elastic search to return related faqs. "FAQ_WEB_SEARCH_TEMPLATE" template to be present.
- if "Enable Web Content Elastic Search as Fallback" rule is enabled, the system will hit Elastic Search to get the related links. "esWebSearchTemplate" to be present.
2) Check if negative sentiment, handle as negative sentiment utterances described in Negative Sentiment section.
3) Customize the behaviour by defining your implementation for the intent named 'not-able-to-classify'. Else "srm_no_result" message is returned.
General error
For any other failures, you can define an error message using message code "default_error", else user will get a default message "I'm experiencing some difficulty in processing. Could you please try again?". Please note any existing transaction state would be cleared.
Context Expansion
What is it
This module expands an incomplete input sentence from the user based on the previous input sentence of the user in a conversation session. e.g.
User Says : How can I get travel insurance ? Followed by : What does it Cover ? It gets expanded to : What does travel insurance cover. This allows users input to be better understood in context of the previous conversation input. Note: Expanded sentences may not be gramatically correct, but it is sufficient for the purposes of various NLP and Q&A processes of Triniti.
Performance Objectives
The expansion is done when required automatically. False positives (Expand when it is not required to) can cause severe usability and experience issue in conversations
E.g.
User Says : what is travel insurance ?
Followed by : how do I contact you
If it gets expanded to : How do I contact you for travel insurance
May create an invalid assumption.
A False Negative is when the module did not expand although it is to be expanded.
Objective of the system is to Minimise False Positives to under 5% and False Negatives to under 30%.
Which means as long as the system expands more than 70% of the time when it is supposed to and expands less than 5% of the times it is not supposed to. The performance is acceptable.
The reason for this is a false negative is easier to recover from for the user, by restating the question or bot asking for additional info.
But a false negative makes assumptions that can throw off the users as they cannot perceive what it may have assumed.
The module has hence been tuned to reduce false positives aggressively at cost of false negatives.
How does the module work
in laymans language.
The module learns the following information from the Project
1. All the Entities and their Values (picked up automatically from NER Data
2. All the valid complete user inputs (picked up automatically from the Classifier Data which is combination of all Smalltalk, FAQs, Queries, Transactions)
3. General knowledge about attributes, verbs from various domains (preloaded with Triniti, but can be appended to enhance for project/domain)
What is does is :
1. it generates all possible combinations by interchanging Entities and Attributes from first and second sentences.
2. It then decides which is the one that makes most sense by scoring them against the Valid complete User Inputs as per the project data .
3. Picks the top one if the score is above the threshold. Else it will not expand the second sentence.
Usual Causes for Failures.
- If the sentence was expanded to “what does travel insurance cover” and if something very similar is not present in project data, it will refuse to expand.
- If the project data itself has incomplete sentences like in FAQs (e.g. how can I get a quote for it) …. It will never expand such sentences as it thinks they are acceptable
- If Entity Values are Ambigous (InsuranceType Should not have Car, Auto, Car Insurance, Home, Home insurance at the same level) if it is it will generate candidates like “how do I buy car” instead of “how do I buy car insurance”
- Some attributes used in the domain are not present in base models of the module. Example : how do I get preauthorisation on it
Fixing Failures
If expansion did not work. Fixing it involves one or more of the following steps. 1. Add the expanded sentence to the relevant project data (FAQ, Intent etc) 2. If it is felt that adding that sentence to that module may cause issues. Add it to Expansions-Hint file. So it can learn it from there. 3. Ensure Every Entity is present in the project NER file. And is Organised properly in hierarchy. Car and Car Insurance should not be the same entity. 4. If attributes are presenting some problems, You will need to prepare domain specific training data so it can append to the base training data that is shipped with Triniti.
Authentication Strategies
Users are allowed to chat with the bot with or without authentication. For channels like WebSDK where without user authentication, there is no specific information known about the user. Morfeus tag them with an application ID which gets stored in the browser as a cookie. Morfeus uses that to tag all the messages from that user under that application ID. In Morfeus, these users are unregistered anonymous users.
For channels like Facebook, even if the user is not logged in, Morfeus uses the user ID provided by the respective channel as the user ID. These kinds of users for unregistered known users. Morfeus only consider authenticated users as registered. Another benefit of authenticated users is, Morfeus can give combined history across multiple channels and multi-channel context.
When a user triggers a flow which is secured, then authentication would be prompted to the user. There are multiple ways to authenticate users, and there are different policies for it.
1) Login at the start of the flow
2) Post-login authentication
3) In-step login
Login at the start of the flow
This is the default behaviour if any flow is marked as secured. Morfeus exposes /authLogin endpoint for custom authentication. Or it also supports standards like OAuth.
Post-login authentication
For SDK channels, you might want to reuse the parent or wrapper application login session. Like if a web application logged in user initiates a chat interaction, the expected behaviour is the bot reuse that session, instead of asking for login details again.
For such scenarios, Morfeus supports post-login authentication. Morfeus can reuse that session, by initializing the SDK with an m-auth header. m-auth is a JSON object with existing session details serialize as String, which server w validate to create chatbot login session.
In-step login
For the better user experience, some prefer to ask for login where it's mandatory to proceed. For that, Morfeus also supports in-step login. You can define in your integration or workflow where you need the user to be authenticated and return the status as 1FA_REQUIRED, Morfeus would take the flow from there and starts the login flow. Once login is successful would return to the earlier flow.
Manage Self Learning
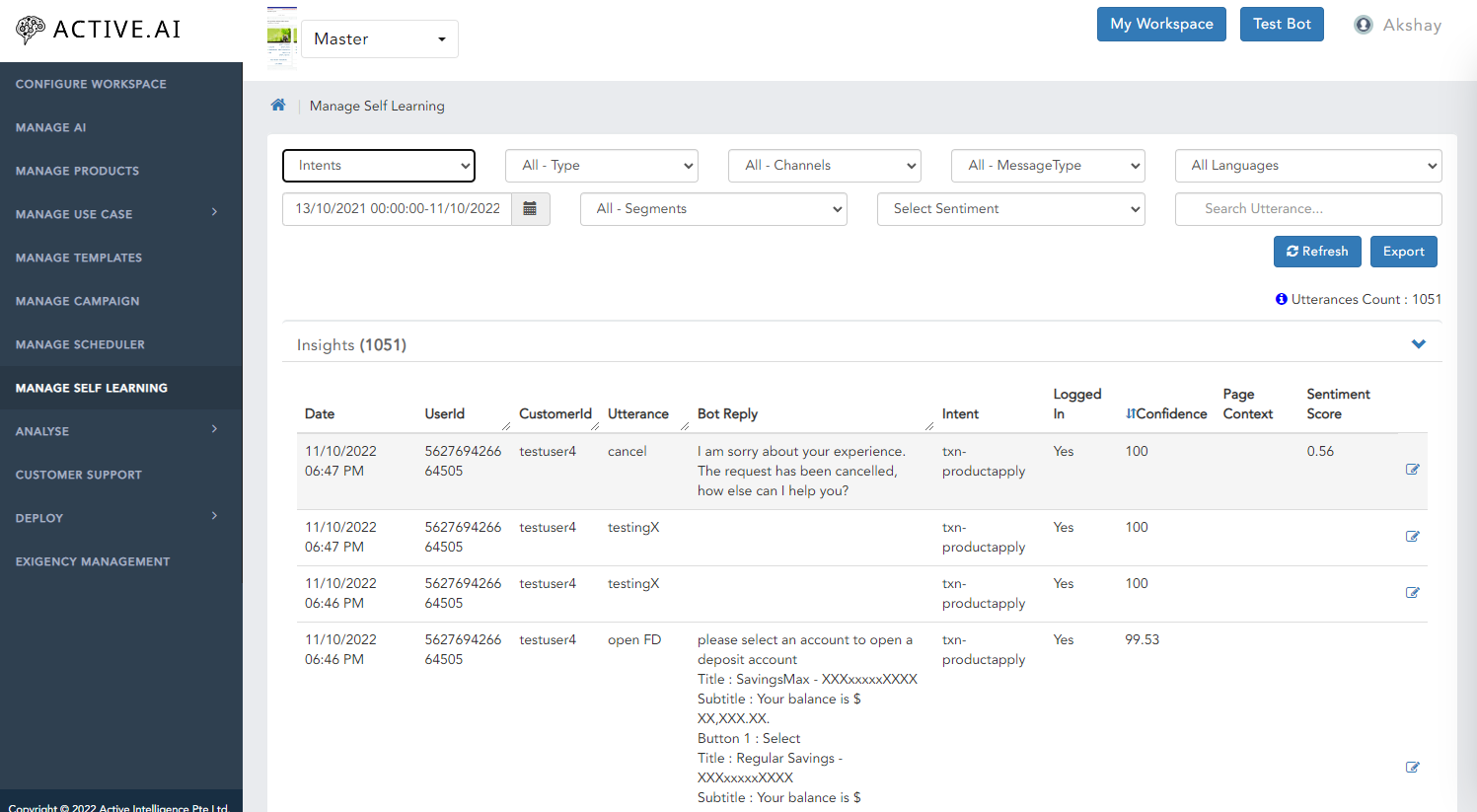
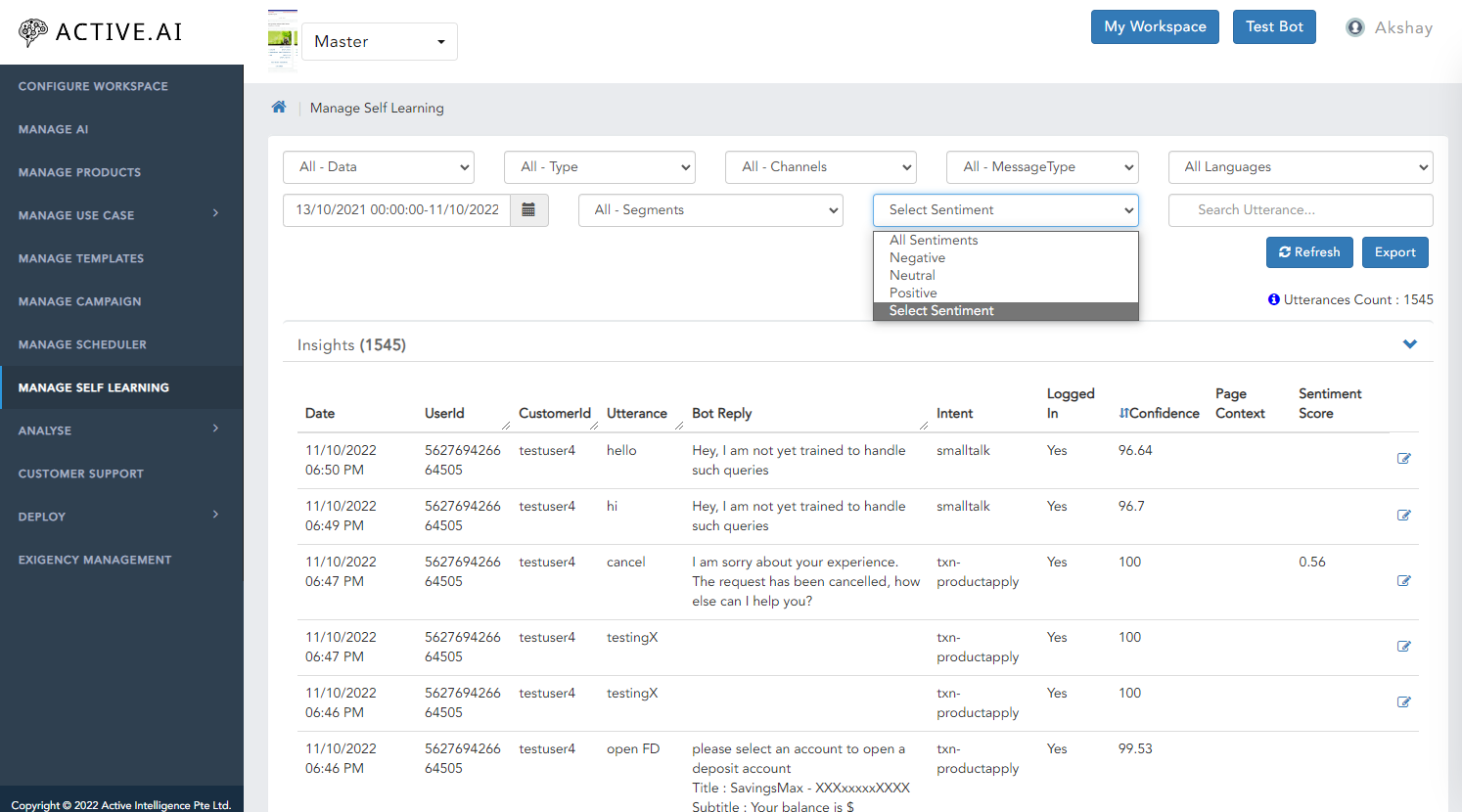
Manage self learning is a feature helps to trace the utterances which are ambiguous, unrelated or unclassified from all sorts of data. This classification can be traced based on Products, FAQ or Small Talk in specific date range as well.
Note: Few options like Intent , entities are not supported for this project.
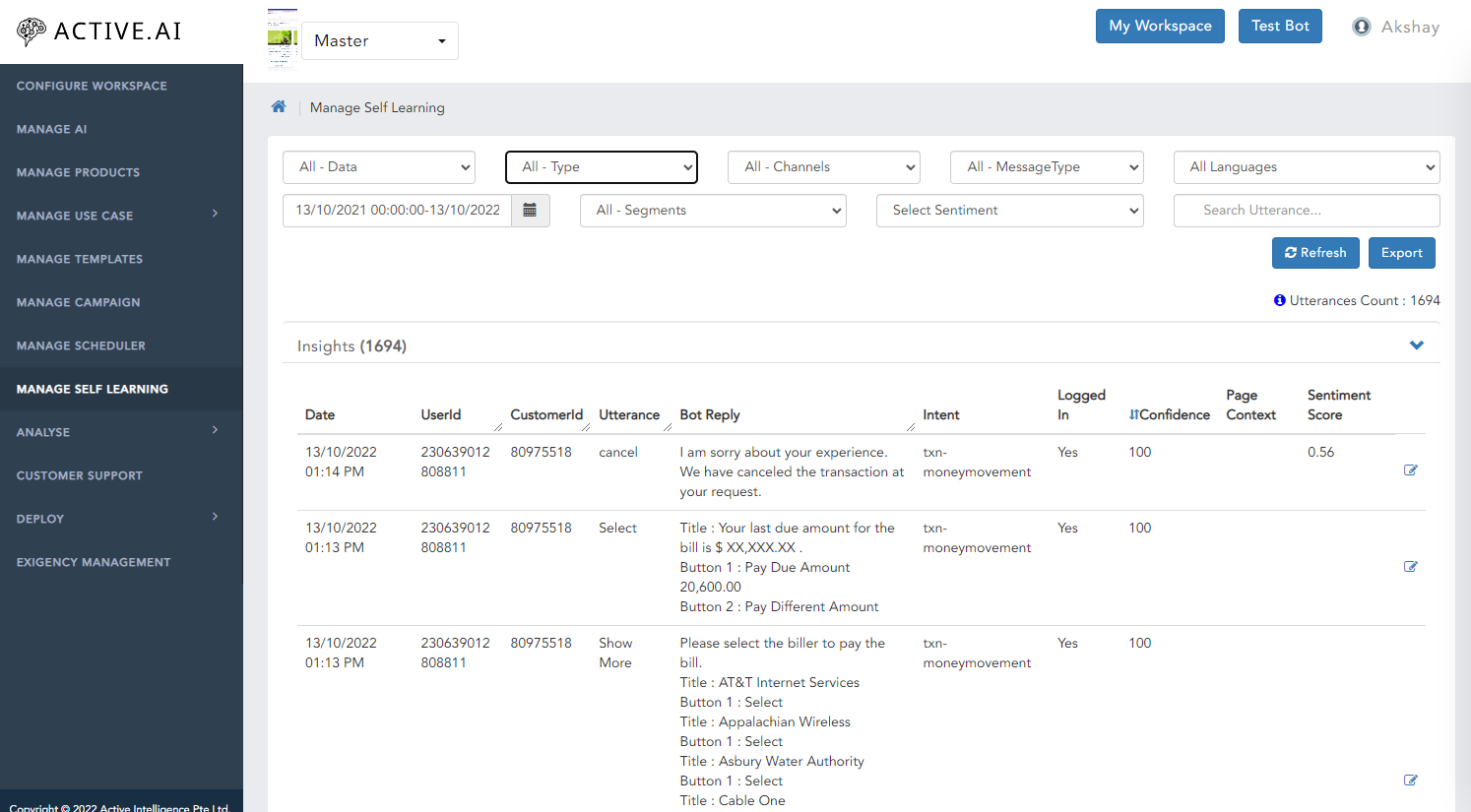
Check All Types of Utterances
We have segregated all types of utterance under Ambiguity, Feedback, Ontology, Profanity, Unclassified, & Unsupported.
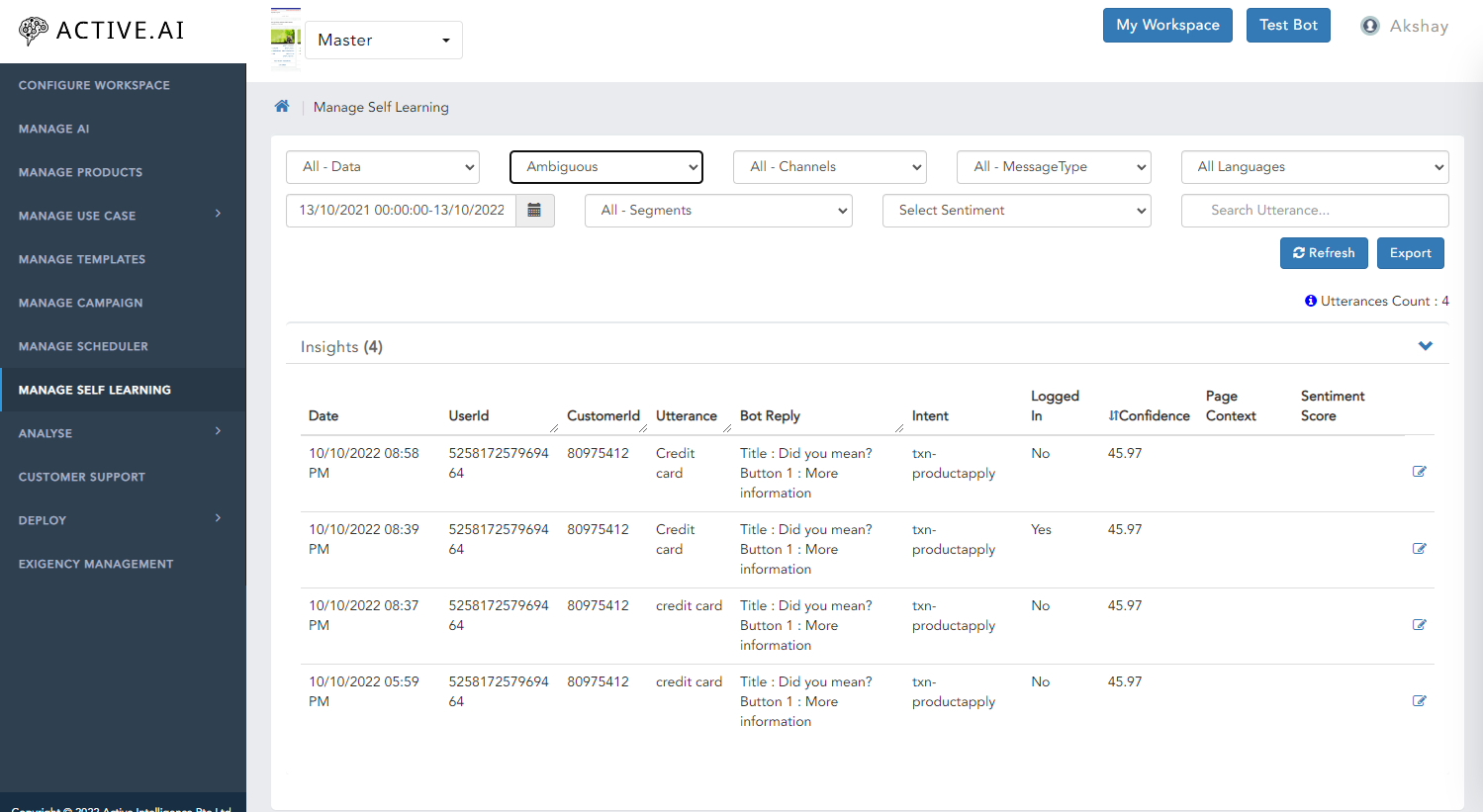
Ambiguous
- Select Ambiguous as Type from the drop down
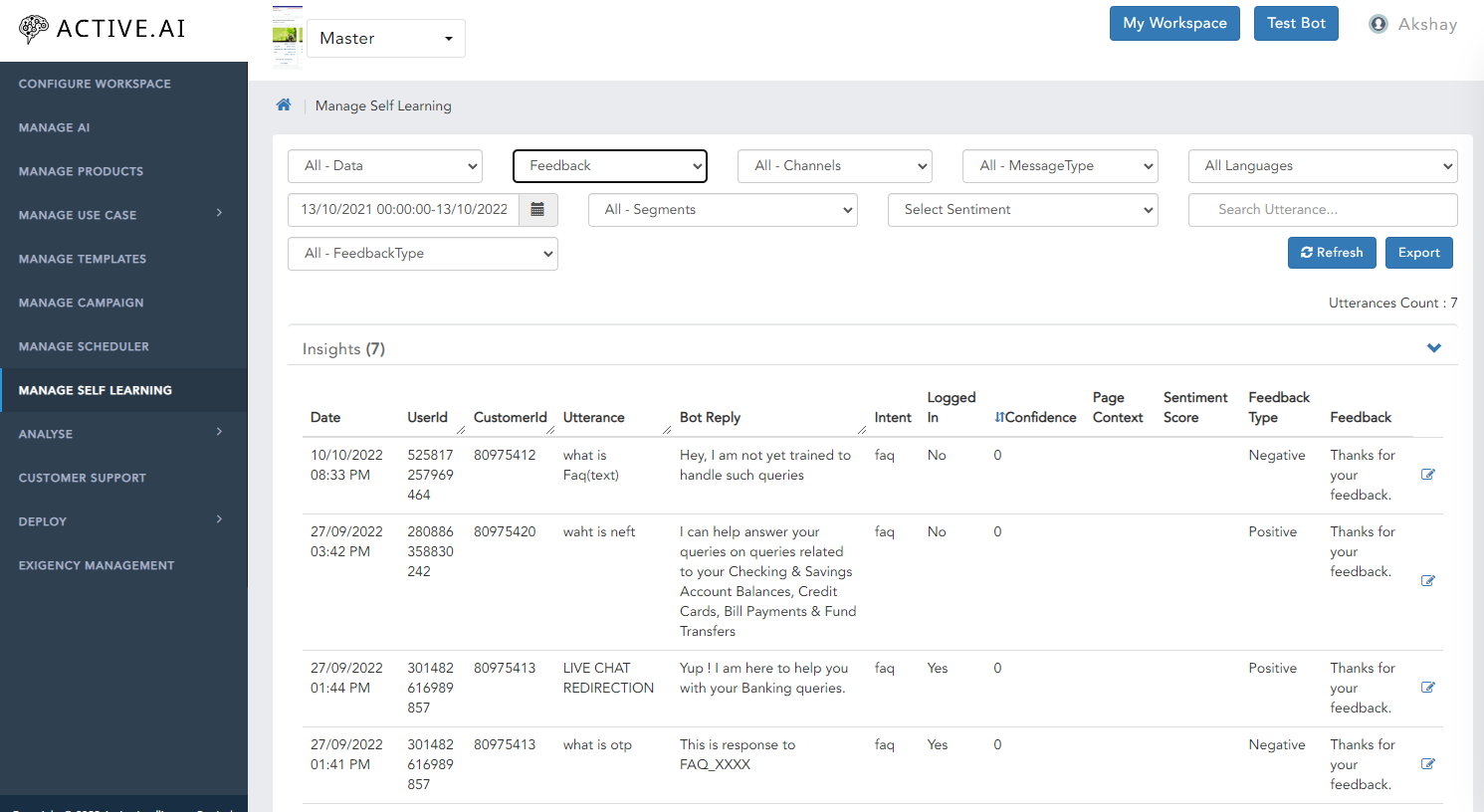
Feedback
- Select Feedback Type from the drop down.
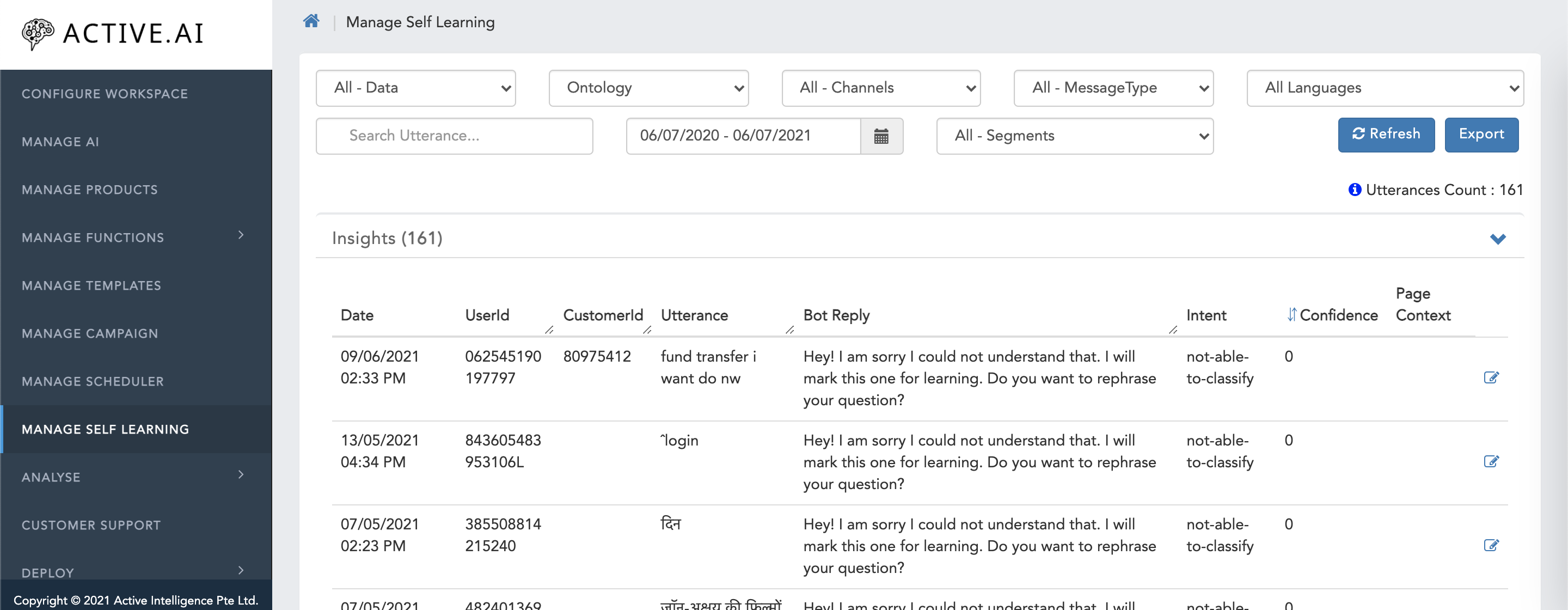
Ontology
- Select Ontology Type from the drop down.
Profanity
- Select Profanity Type from the drop down
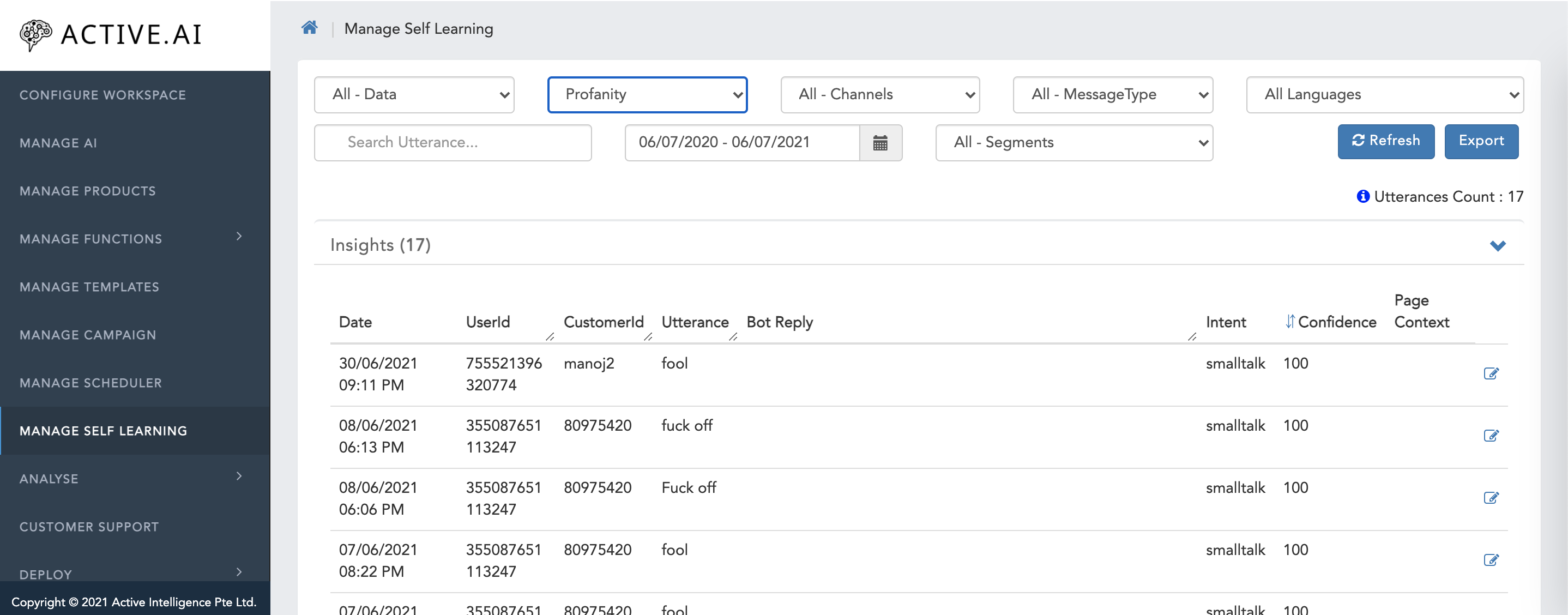
Unclassified
- Select Unclassified Type from the drop down
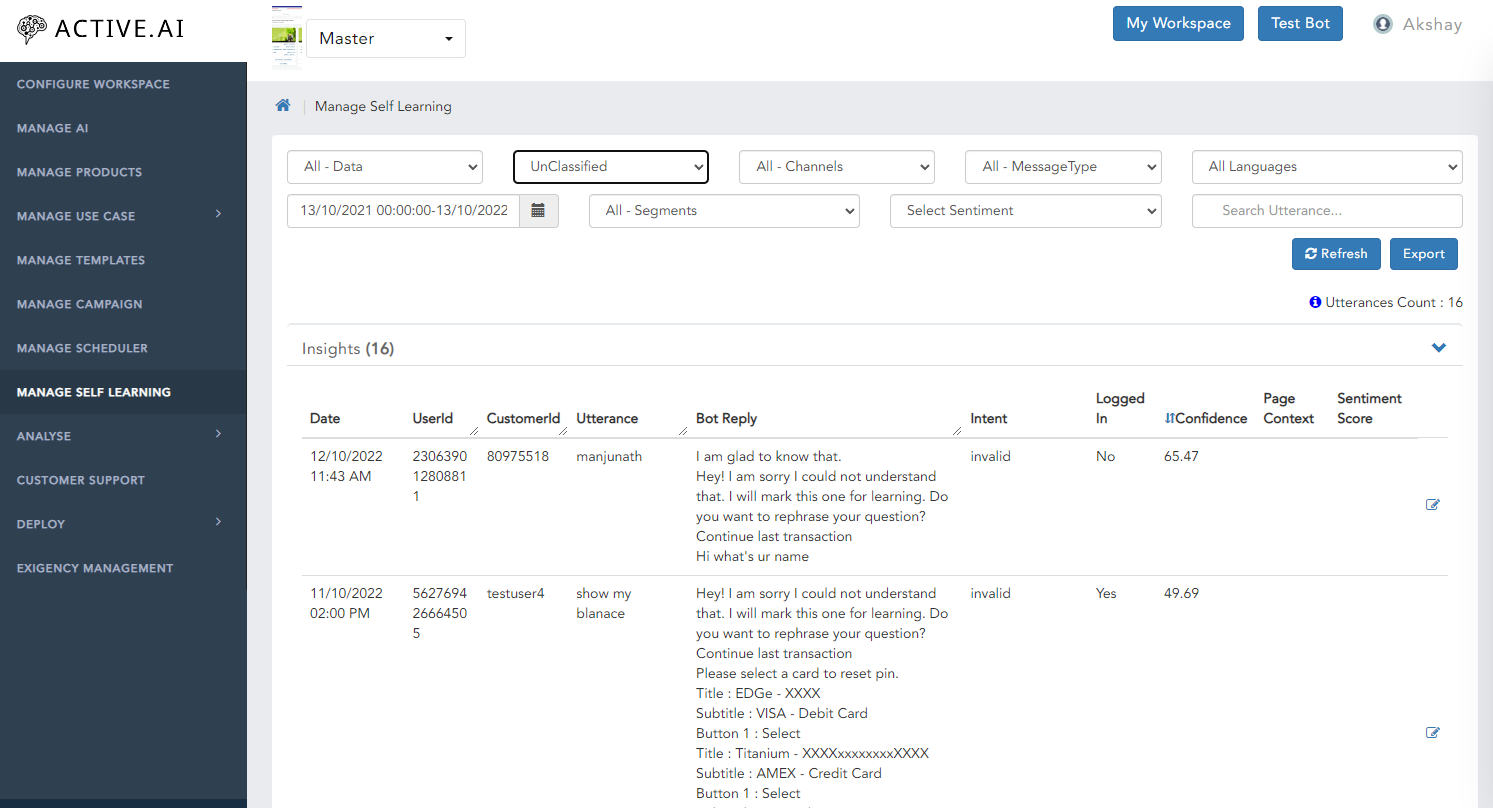
Unsupported
- Select Unsupported Type from the drop down
Search by Data
Search by data is nothing but checking the utterances of FAQ's, Small Talk, Banking with respective to Channels or Type of Answers.
FAQ's
- Select the FAQ in Data

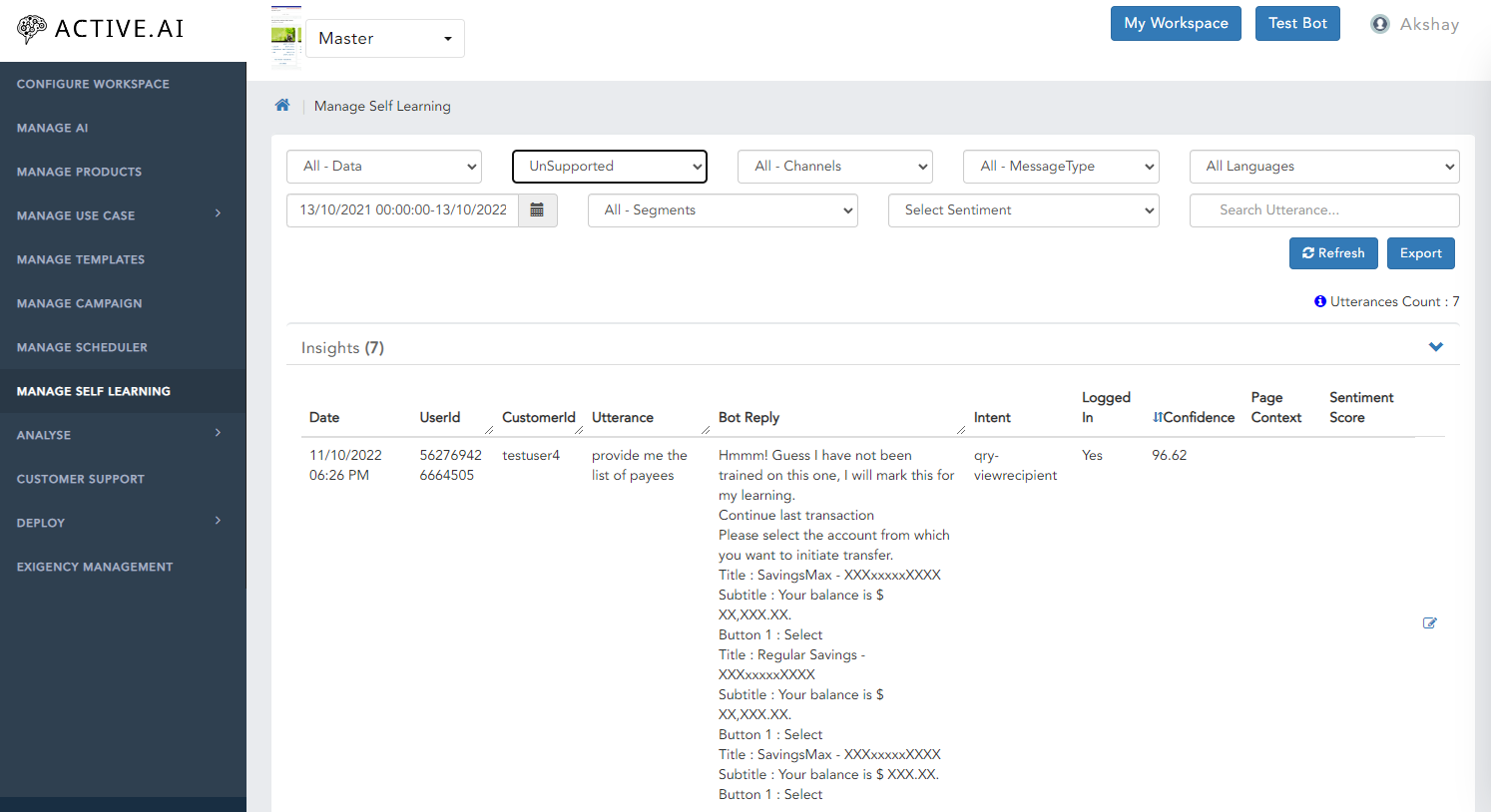
Small Talk
Select the Small Talk in Data.
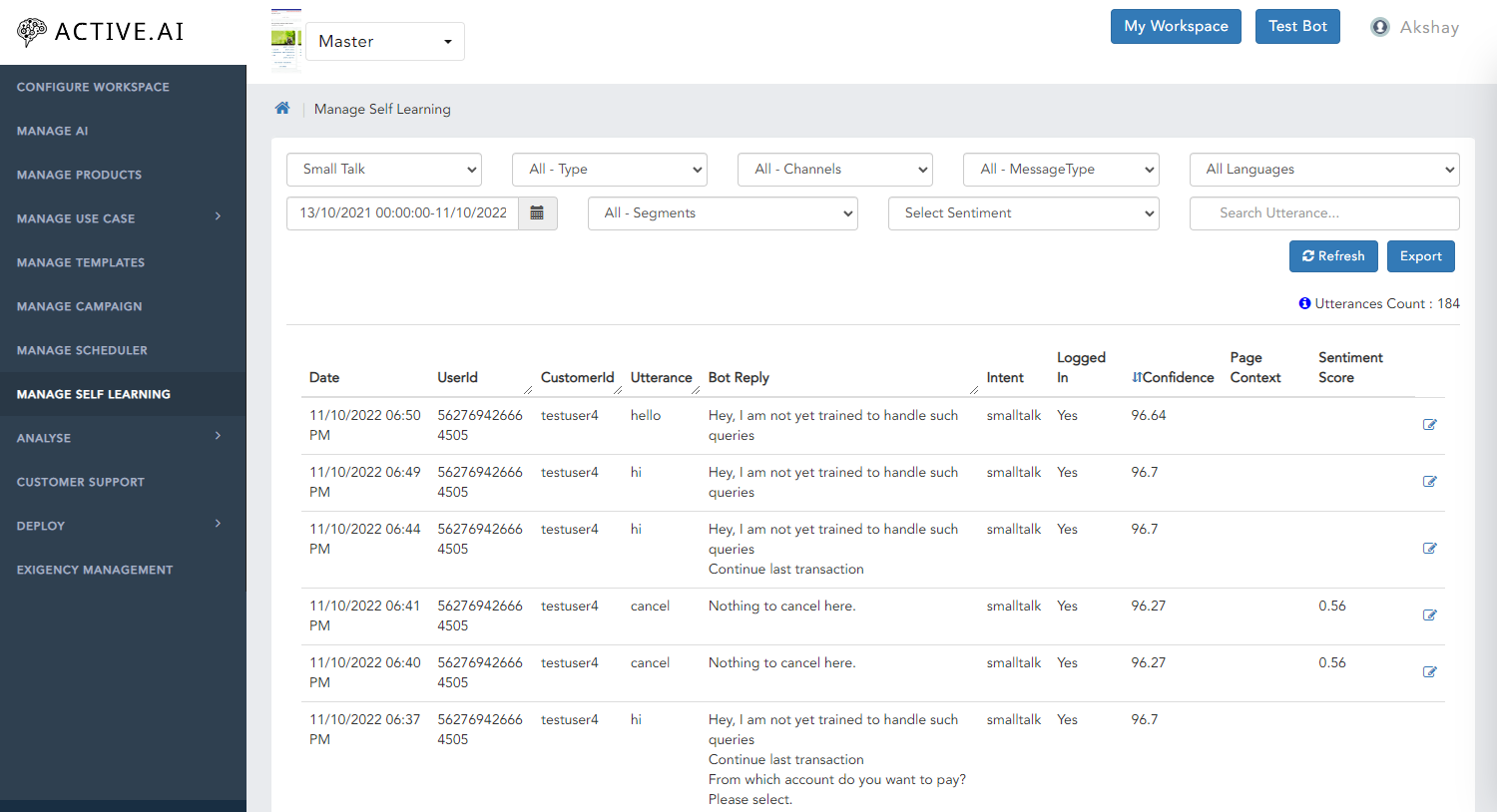
Intents
Select the Intents in Data
Search by Customer Segment
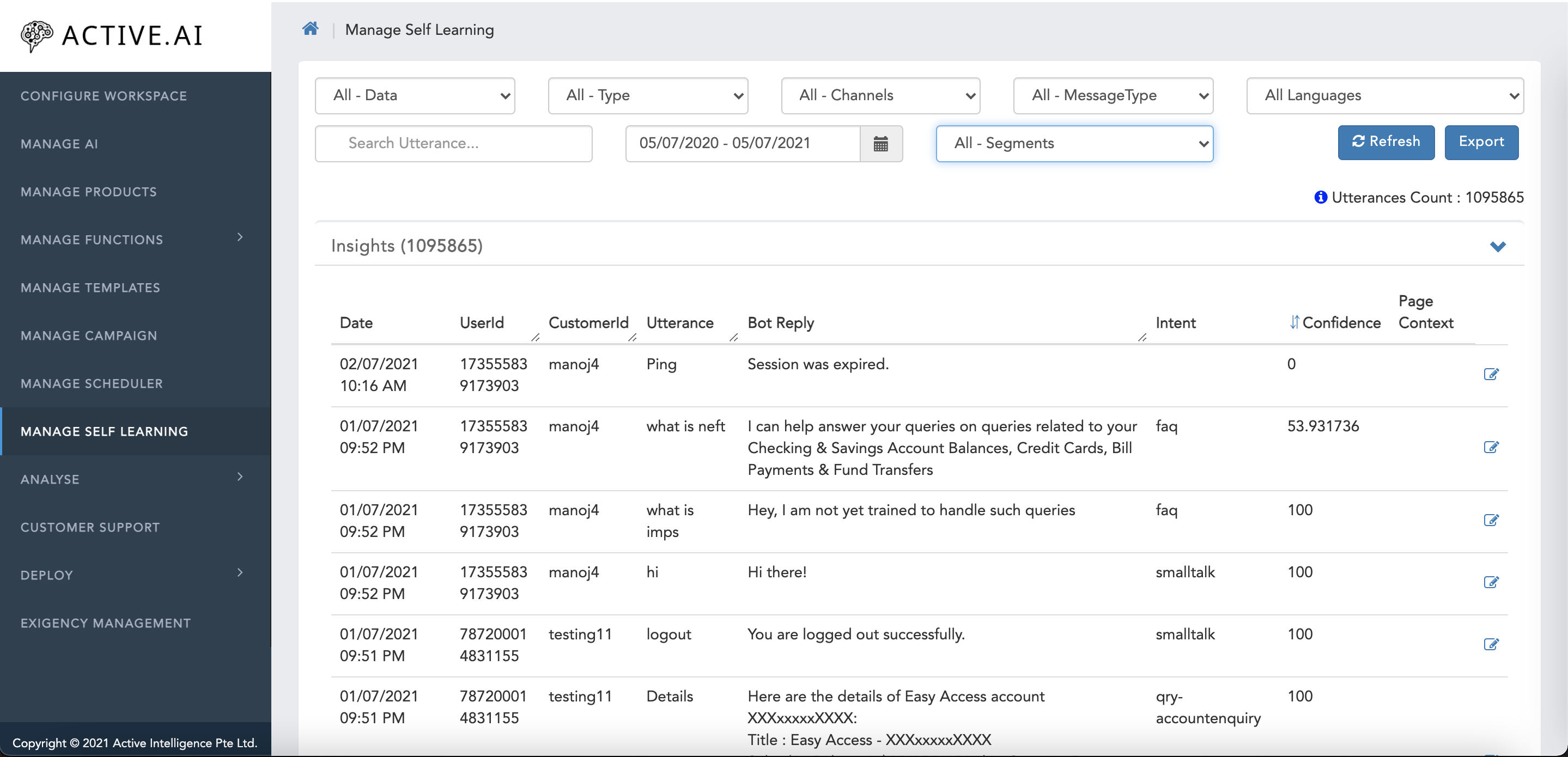
Search by customer segment lets you to filter the utterances based on customer segment.
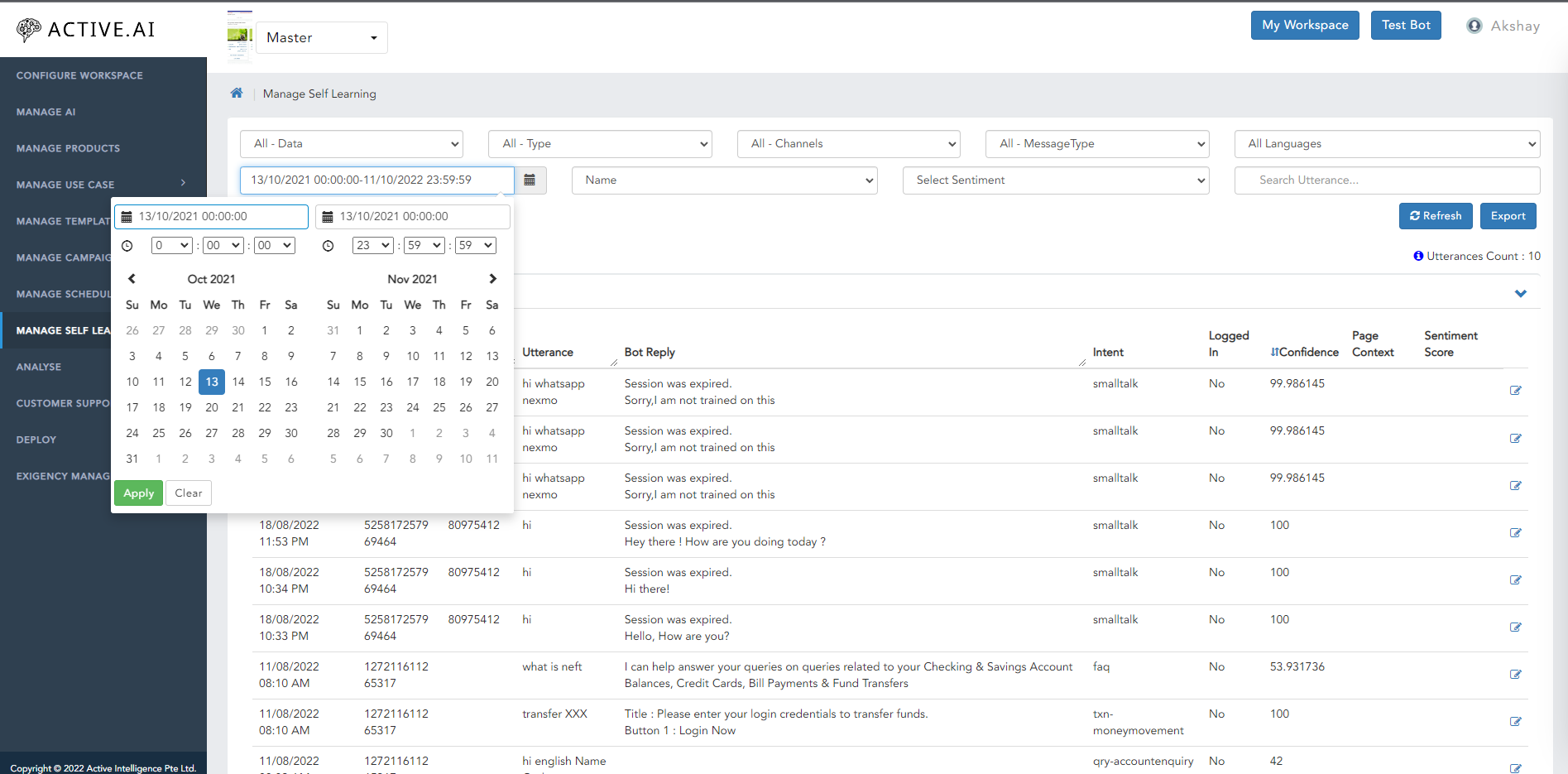
Search by Date
Search by date is nothing but checking the utterances of FAQs, Small Talk, Banking with respective to Channels or Type of Answers in between the date range. Using the calendar specify the From & To dates.
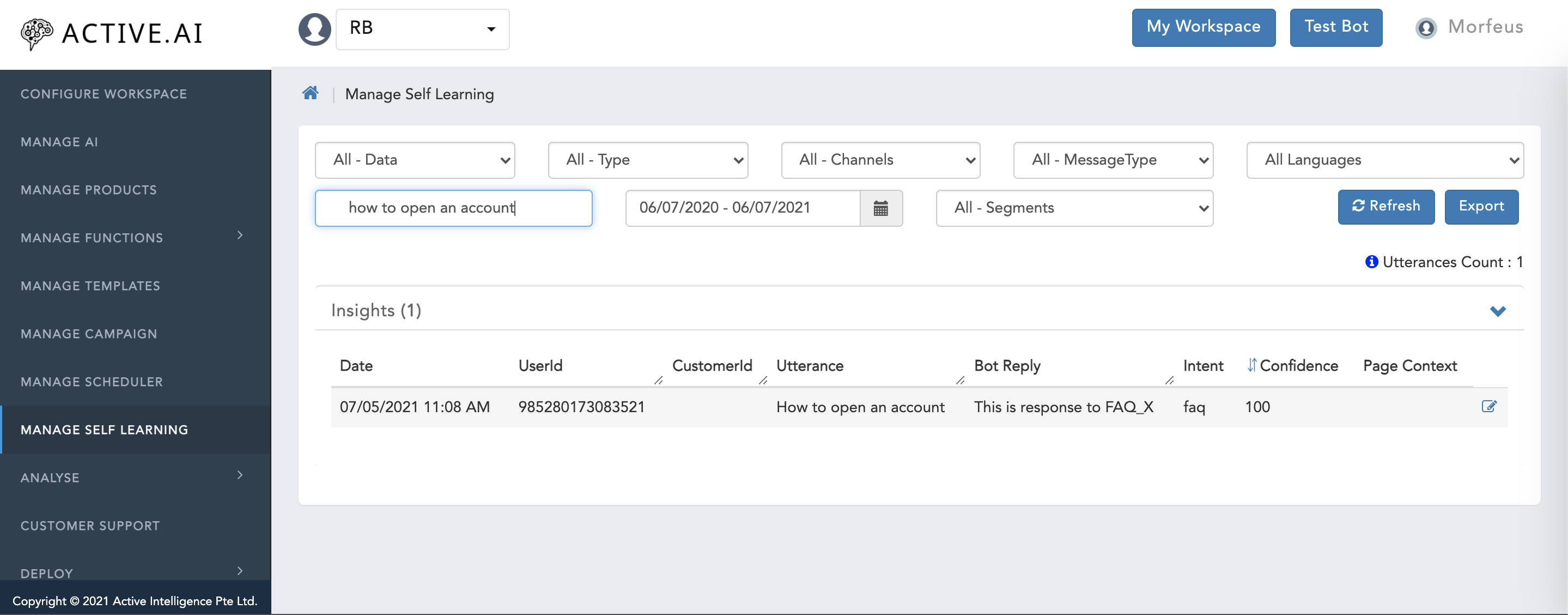
Search by Statement
Search by Statement is a combination of selecting the utterances of FAQ's, Small Talk, Banking with respective to Channels or Type of Answers using key statements provided in the input field.
Search by Sentiment
Search by sentiment let you filter the utterances based on postive, negative or neutral sentiment.
Adding Utterances to Data
Adding the Utterances to existing or new datasets will help to guard the leakage.
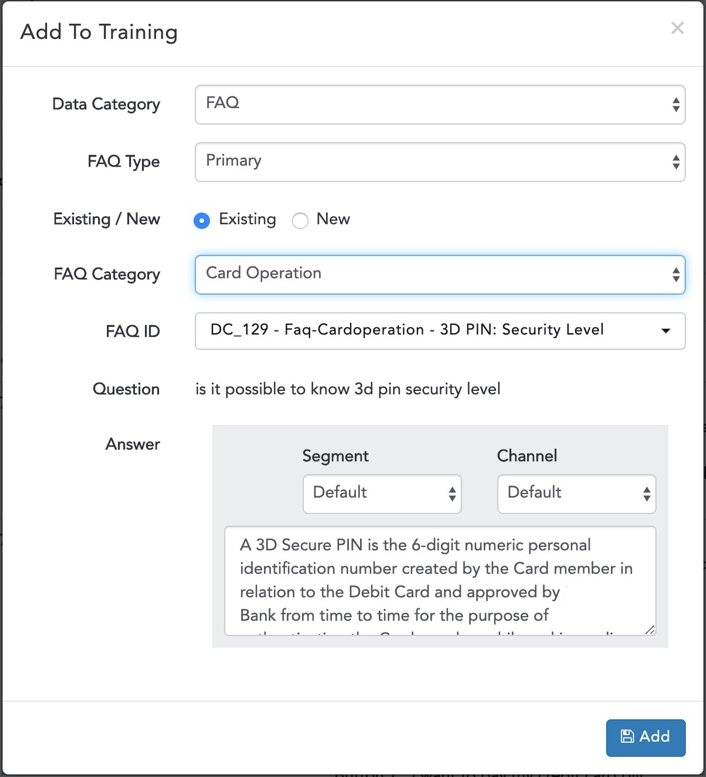
Existing FAQ's
To add in to existing FAQ's set,
- Choose the utterance.
- Click on the edit icon in end of same row.
- Select Data Category as FAQ.
- Select FAQ type as Primary.
- Select Existing.
- Choose the FAQ Category. (if requiries)
- Select FAQ ID
- Click on Add.
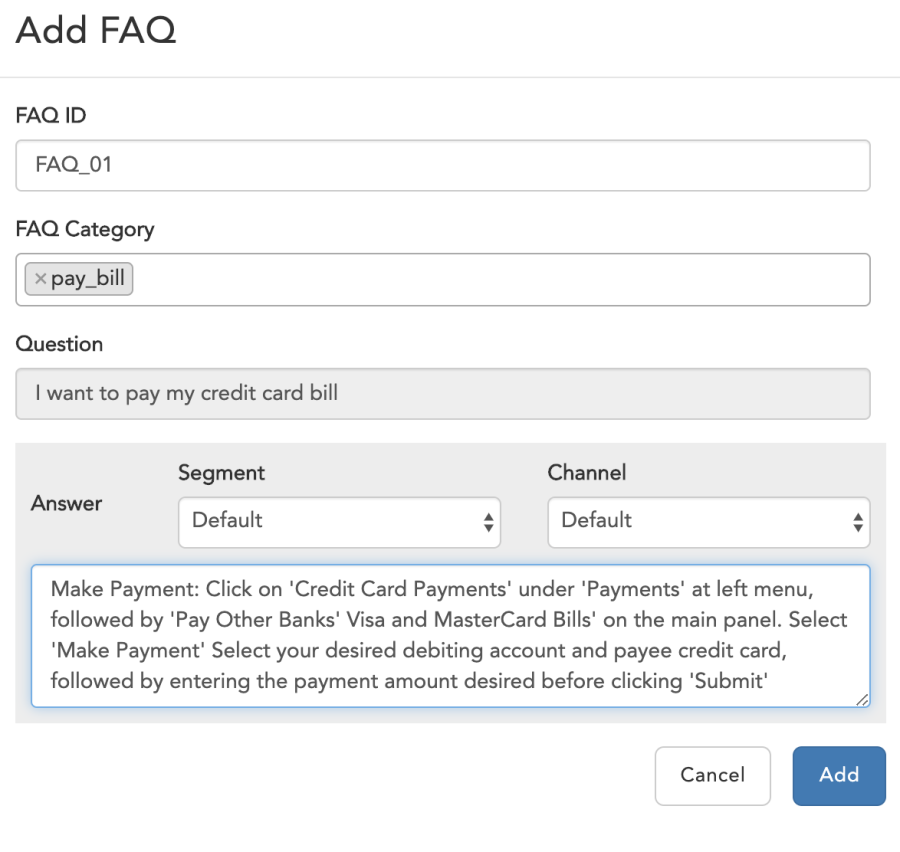
New FAQ
To add in to New FAQ's set,
- Choose the utterance.
- Click on the edit icon in end of same row.
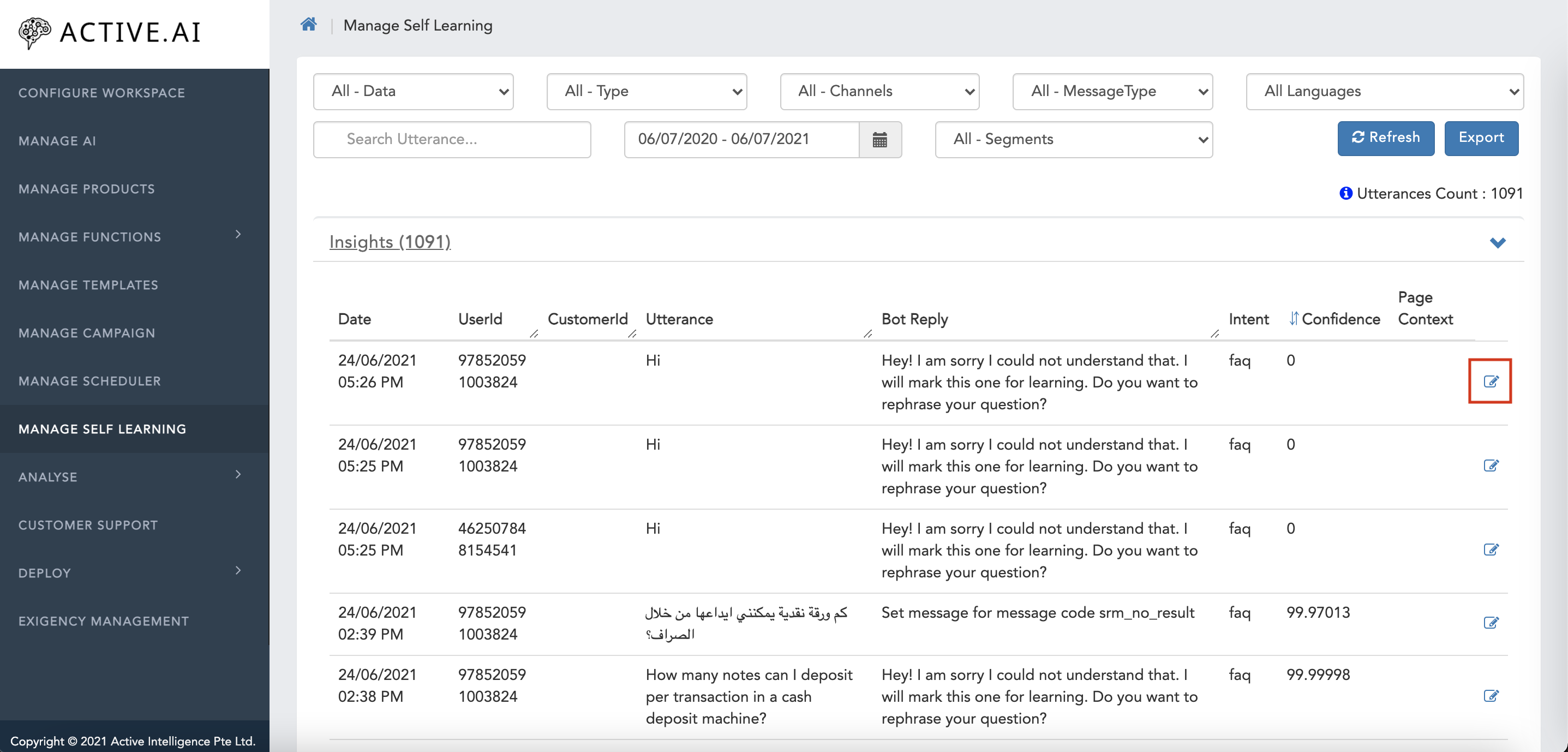
- Select Data Category as FAQ
- Select FAQ type as Primary/Secondary.
- Select New.
- Click on Add.
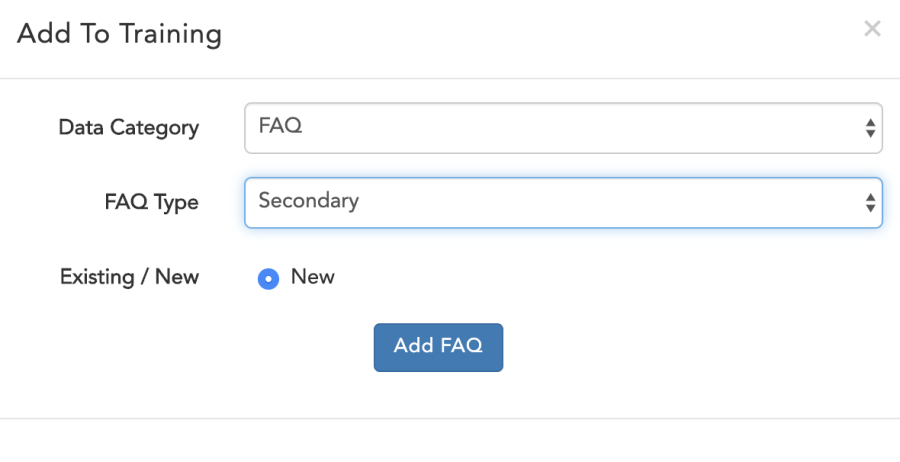
- Fill the input details like FAQ ID,Category, FAQ Response
- Click on Add.
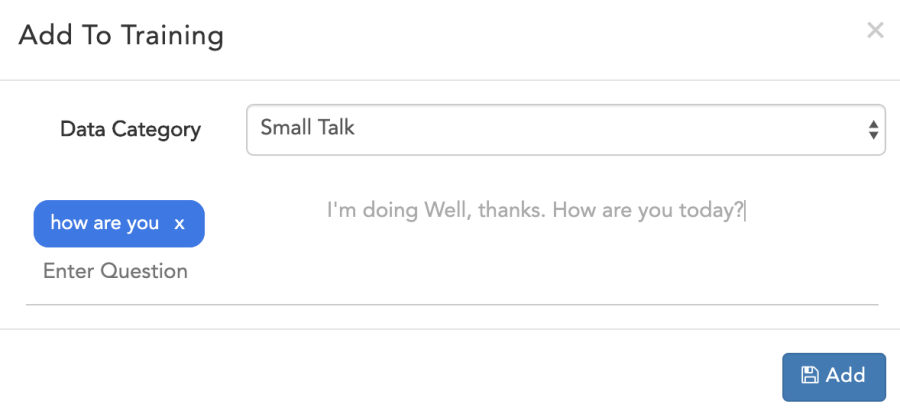
Small Talk
To add in to Small Talk set,
- Choose the utterance.
- Click on the edit icon in end of same row.
- Select Data Category as Small Talk.
- Enter the Question & Answer
- Click on Add.
Analytics
Analytics will help to know the overall statistics of bot & AI Engine, which gives the much details in terms of Users, Accuracy, Channels, Domain, etc…
Overall User Report
- Select the Analysis from Hamburger.
- View the report.



User Drilldown for Whatsapp
We are showing drill down details for whatsapp channels. To view this we have to enable one rule. Go to Manage Workspace Rules search for 'Drilldown On Registered User Analytics' and change the value to true, now in analyse dashboard select Whatsapp channel and click on Users(till date).

We can filter the report based on Date (Daily, weekly, Monthly, Yearly) with Domains (FAQ, SmallTalk,etc…), Channel(Web App) and Customer Segment.
Using this report, we can do detailed analysis on Accuracy obtaining, No of Logged in Users, NewUsers, Total Session in range, Live Chat Redirections, Feedback percentage and many more.
Export functionality is also available we can either export pdf or excel.
Redirection is also allowed on the bubbles containing arrow on top-right corner we can redirect to user report, transaction report, service request reports , enquires and self learning.
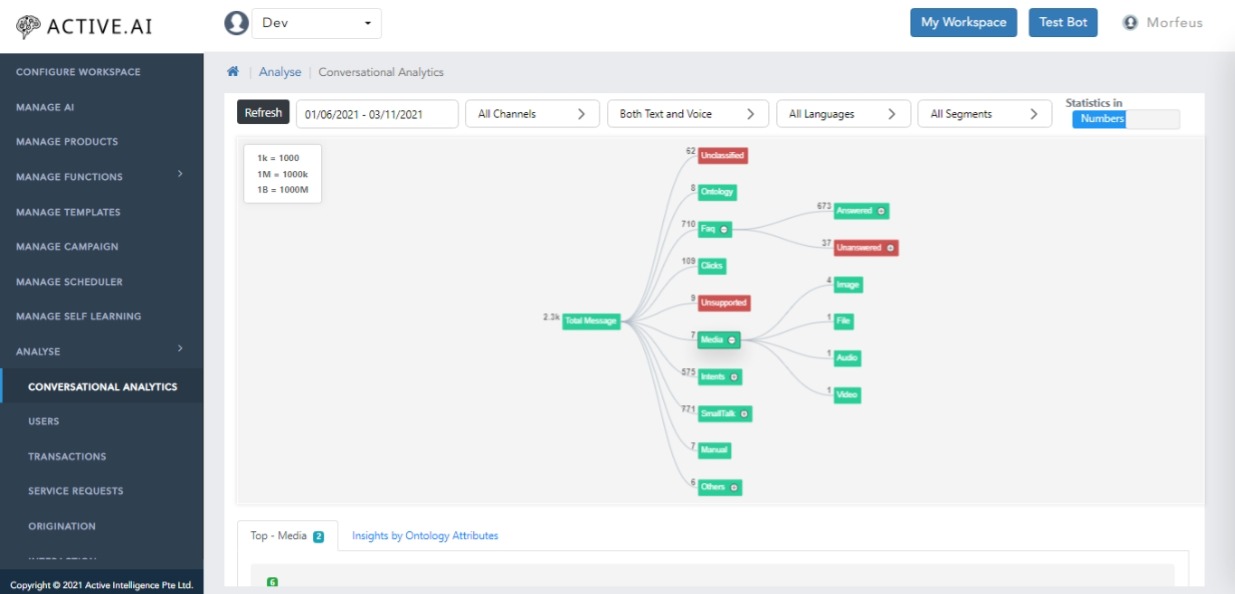
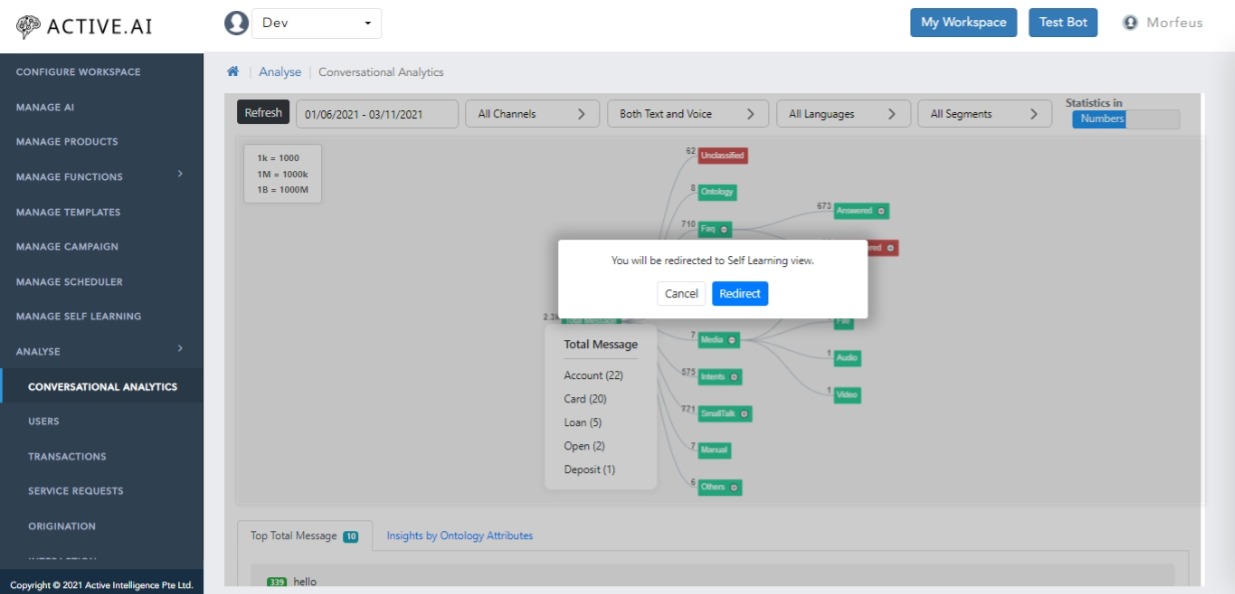
Conversation analytics
- Select the Analyse from Hamburger then Conversational analytics
Here we are showing the graph how conversation is behaving.
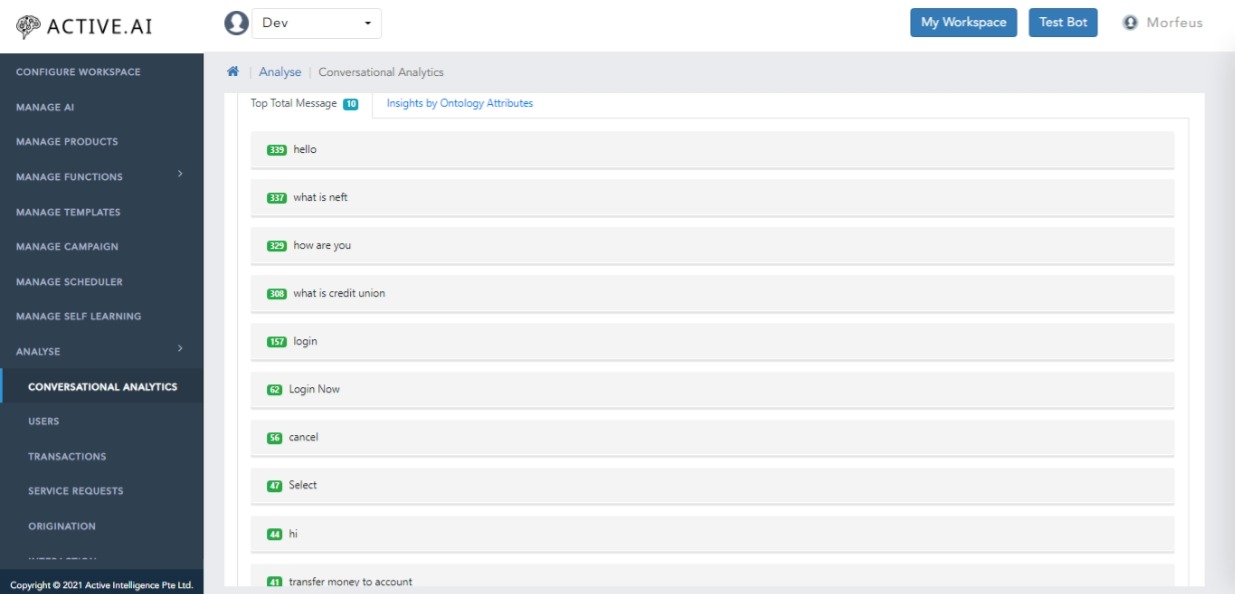
Starting from 'Total message' node we are splitting it into different categories like Unclassified, Unsupported, FAQ, Intents, Media, Smalltalks and many more. Also on click of any node we can see top 10 messages and on right click we can see top products or we can redirect to self learning.
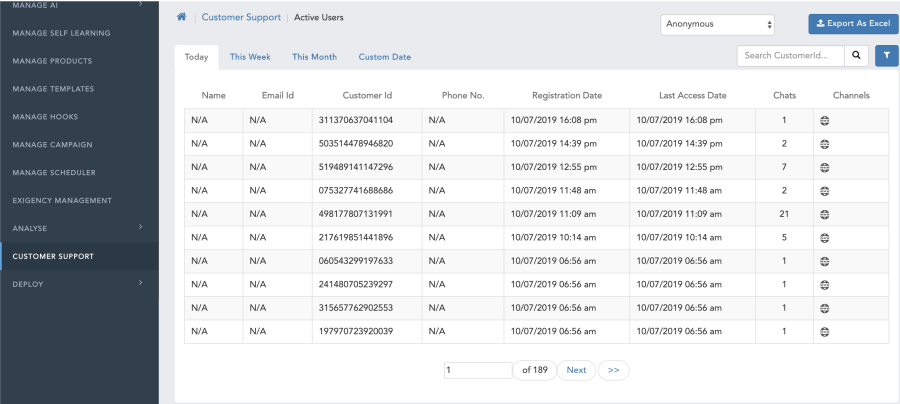
Customer Support
Customer Support has complete details of user based on customer id, phone number, & from Channel where interacted. Using this we can easily find Registered Users or Anonymous. Search option is also available filter by entering Customer id also.
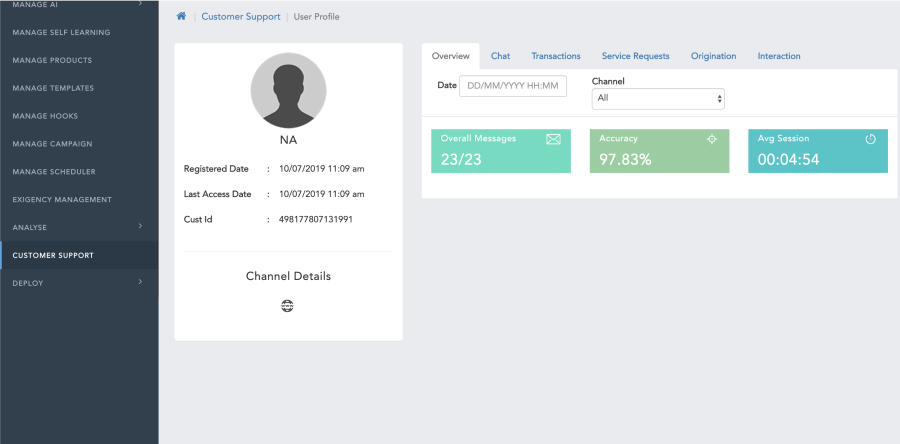
- Click on a record will opens the details.
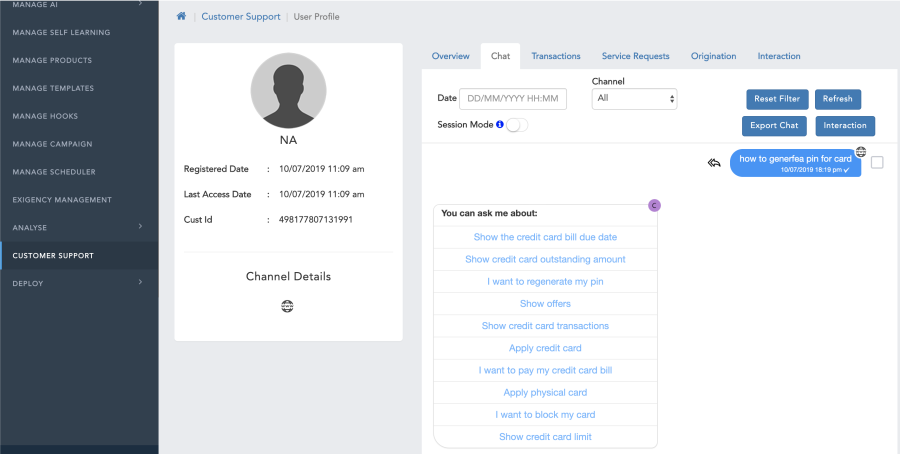
2. click on Chat will open the utterance user tried.
Transaction and Service Request custom implemenation
For faster downloads for transaction and service request reports. In this, we will be excluding the reports.json file while processing the records.
We can still use the reports.json to do that just make change the following rule, goto Manage AI rules -> Reports and look for 'Enable Handlebars engine for reports’.
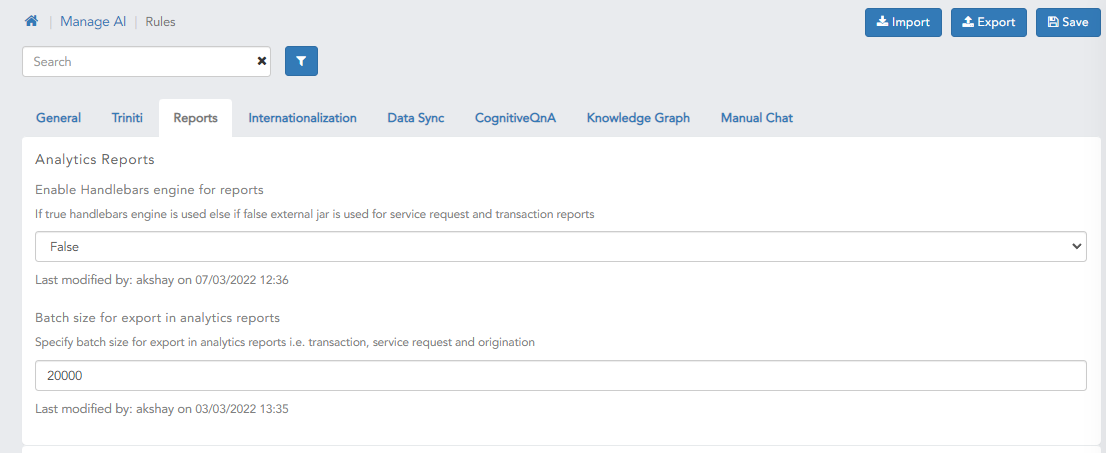
If the requirement is to use custom implementation then follow the following steps:
Make the desired changes in the admin-extension project Admin-Extensions Link.
Select the desired column that needs to be shown/exported in reports and build the jar using mvn clean install.
Now in the tomcat folder create a new folder named morfeusadmin-lib and paste the admin-reports jar.
Now copy-paste the following XML file with the path of morfeusadmin-lib folder, inside conf/Catalina/localhost.
morfeusadmin.xml
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resources className="org.apache.catalina.webresources.StandardRoot" cachingAllowed="true" cacheMaxSize="100000">
<JarResources
className="org.apache.catalina.webresources.DirResourceSet"
base="{EXTERNAL_LIB_LOCATION}/morfeusadmin-lib"
webAppMount="/WEB-INF/lib" />
</Resources>
</Context>
Restart the tomcat and you are good to go.
FAQ's Best Practices
Please use this document as a guide to support cognitive QnA in the chatbot you are building.
Your Cognitive Q&A Bot has the following features that you can customise.
1. Answers Questions about your products, services or processes that user may have.
2. Answer to Smalltalk
3. Give canned answers for out-of-scope queries
4. Understand Context of the Conversation while answering user queries (Paid Option)
5. Lead Generation
6. Handover to Live Agent (Optional for Launch)
7. Bot Messages, Handling Profanities and Settings.
8. Analytics on Usage and Retraining
Data Strategy
How can you add FAQ data
There are three ways you can get started.
1) IMPORT a CSV with all your questions and answers. Check the format here.

2) ADD questions and answers manually one by one.

3) Start off using our pre-built data sets and just customise the answers.
Note: You may choose to categorise your questions for easier management. Our prebuilt datasets are always categorised.
Generic features
Source for questions
Here are a few key data sources you can look at to optimise the questions
Website search history - look for what customers are searching for in your website? If a lot of people search 'NEFT timings', SWIFT code' it makes sense to have questions like 'What are NEFT timings' , 'What is AXIS bank SWIFT code' etc
Contact center records - One of the objectives of cognitive QnA assistant is to free-up your contact center staff time from mundane stuff and make them available for cases where they can add more value like help in deciding the type of loan or credit card OR to address a dispute. Hence, we strongly suggest looking into the e-mail and call transcripts to identify the top 20-30% queries in terms of volume and design QnA around the same.
Queries on key features of each product or service
Queries on the various channels availability
Welcome message
When user invokes the bot on any platform, you can show a welcome message to set the tone for the conversations that yield best results. Instead of saying things like 'ask me anything' , you can specify exact things like "you can ask me stuff like 'how to apply for a credit card', 'what are NEFT timings' etc" to give a direction to the user.
Here are a couple of examples




Sample welcome message text
"Hi! Glad to be at your service. I can answer you queries on products and services of AXIS bank. I can also help if you want to who our CEO is and so on. You may ask things like
Who is the CEO of axis bank?
What is a credit card?
Why was my loan application rejected?"
Closed ended vs Open ended questions
Differentiate questions with boolean/closed ended answers from descriptive ones for better efficiency. This way the
Ex: Do not include 'are there any charges for signature credit card' as a variation of 'what are the charges on a signature credit card'. Instead train them as two different questions, with similar answers but you can add a affirmation like 'Yes!' etc to the former
Scope of questions for the conversational channel
It is important to define the scope of the questions that will be supported on the conversational channel. Broadly a user may come to the conversational channel for things like
- Details of a product including application process, eligibility, charges etc which would help them decide
- Generic info on a service like process of applying for a cheque book
- Specific details on a process like RTGS fund transfer like charges, availability etc
- A grievance masked as a question like 'why my credit card application was rejected?'
Here, we present the broad areas with few examples
- Product discovery FAQ
- Features (apply, eligibility, charges)
- Comparison
- Service related FAQ
- Availability
- Fees & Charges
- General customer education / financial literacy
- Include suggested ratio/mix in terms
- Channel based responses
- Information about the institutional profile - history, management, financial results etc
Key AI features
~Coming Soon~
Confidence threshold
The bot answers a question only if the confidence level is fairly high. By default, this has been set to 0.8. You can change this based on your data and testing results. Setting it too low will cause a lot of false positives while setting it too high will block off many correct answers. The setting should balance correct answers against false positives.
Conversation context
Enabling this feature allows the bot to understand the current question in context on the previous question of the user. e.g. Ask "How do I pay the premium due". Followed by "what if I pay it late"
This feature is not available for free workspaces and is a paid option for other workspaces.
Keyphrases
A Keyphrase is a word/phrase that must be present in the user's query in order to consider it as a potential candidate for answers.
Example "How to pay my credit card" can have "credit card" as the key phrase.
Since users may type the key phrase in different ways you may also want to declare "credit crd" "CC" as variants to these Keyphrases so they are all treated equal.
Keyphrases are used to narrow down the potential candidates against which the Cognitive Q&A module runs matches against. Quality Key phrases are important for accurate responses of the bot.
By default, the Cognitive Q&A module generates Keyphrases automatically. But it is important that you review these for best performance.
You can review Key Phrases against each question or review all Keyphrases in the overview or questions list page. Keywords are also bordered by a bounding box on the questions list page.
Out of scope queries
At the time of going live, your bot may not trained to answers questions around every product/service that you offer. In order to catch and give a customized response when the user asks about these products/services, you can map canned responses against each product/service.
Provide synonyms and variants for each product/service so that every one of them is caught and responded to with the canned response.
Profanities
We have preloaded a lot of profanities here that will be blocked and handled appropriately. You can simply add to this list one per line.
Similar questions
The bot can be enabled to respond with similar questions to the user under various circumstances
[ ] If there is no response
[ ] If the confidence is below a chosen threshold
[ ] Every X queries asked.
You can enable one or more of the options above.
SmallTalk
We have preloaded most commonly used smalltalk with some answers. You can customise the answers or Add additional smalltalk into the system.
Each Smalltalk can have multiple answers. The bot will pick one randomly each time so it does not sound too robotic.
Spelling correction
Spelling correction is automatically enabled in your bot. It is trained automatically and you do not need to do anything else. In order for it to work well remember not to never use wrong spellings or Lingo in the Questions and Answers that you provide.
If your users are prone to typing into certain lingo, such as "Txn" instead of "transaction" you can declare them here or as Keyphrase variants if it is key phrase.
Training and Testing
Click on TRAIN icon to train the bot with the latest data set.
Once training is complete you can test the Bot by clicking on the "TEST". You can always test the previous version of the bot while Training is in progress. Once the training is complete, the version of the bot is is automatically updated with the latest trained data.
You can view the debug information during testing in the Debug Panel of the Test Bot. This provides information such as preprocessing done, Keyphrases identified, Candidates Considered, Scores, etc.
Automated Testing
You can automate testing and have the results emailed to you. Simply upload the test file into the test bot in the format here.
Unknown words
Unknown words are highlighted in red bounding box. It is recommended that you create variants for such questions to cover variations or phrase equivalents of those unknown words.
Keyphrases and how to curate them
Formatting FAQ Responses
Various types of responses can be curated and presented in different formats based on the nature of the question and sophistication required
| Table 11 Formatting FAQ Responses | ||||
| Response | Type | Ref | HTML tags required? | Suitable for |
|---|---|---|---|---|
| Simple text | Text | F1 | No | Simple definitions or affirmations |
| Text response with hyper-links abbreviated as 'here' | Text | F2 | No | Where as part of response user is required to refer to a web page for additional info |
| Text response with hyper link embedded | Text | F3 | Yes | When response is complete in itself but user can click built in links for more info |
| Text response with formatting like lists, bold, alignment etc | Text | F4 | Yes | When response involves steps of a process or feature lists etc |
| Text response with CTA (1 or more) | Text | F5 | Yes | A response that answers a question sufficiently , but also prompts user to perform related actions like block card after a query related to the process of blocking |
| Text with built in quick links | Text | F6 | Yes | To present key pointers related to the question |
| Text response with related questions embedded | Text | F7 | Yes | In cases where the question is just one of many more related questions that could give clarity on the topic. Ex: after inquiring on a product features, user may be interested in the associated fees & charges |
| Card with button | Template | F8 | May be | Response involves text + CTA. CTA can be link to web-page or built in flow etc |
| Carousel | Template | F9 | No | To explain variants of a product or present list of offers etc |
| List | Template | F10 | No | When the response if usually a list of options like say 'ways to for funds transfer' , 'types of loan offered' , 'statement frequency supported' etc |
| Custom | Template | F11 | Yes | When different features are required that are not OOTB but available elsewhere and can be linked |
| Combination | Template | F12 | No | The templates can be combined in any manner based on requirement ex: Text with CTA followed by a list etc |
| Trigger a chain of events | Workflow | F13 | May be | As part of response , some user inputs in the form of text or selection may be required to provide the most appropriate answer OR when a business process needs to be executed like 'apply credit card' can be a work-flow following a query on credit card product features |
***Note:
- All templates responses can have an optional 'speech response' as input
- A combination of templates is possible
- Quicklinks, buttons are standard features available for any template response
Sample FAQs to show response variations
- F1 - F7 are text responses
- F8 - F12 are template responses
- F13 - is a Work-flow response
F1 - Simple text

F2 - Text response with hyper-links abbreviated as 'here'
Sample response text: You can find the charges for Axis Bank Platinum credit card online by clicking https://www.axisbank.com/retail/cards/credit-card/platinum-credit-card/fees-charges#menuTab
F3 - Text response with hyper-link embedded
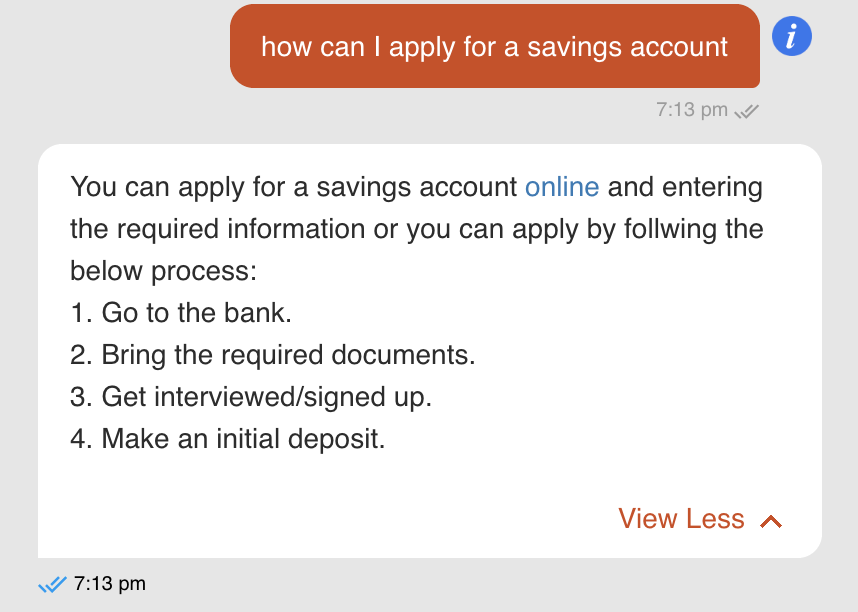
F4 - Text response with formatting like lists, bold, alignment etc
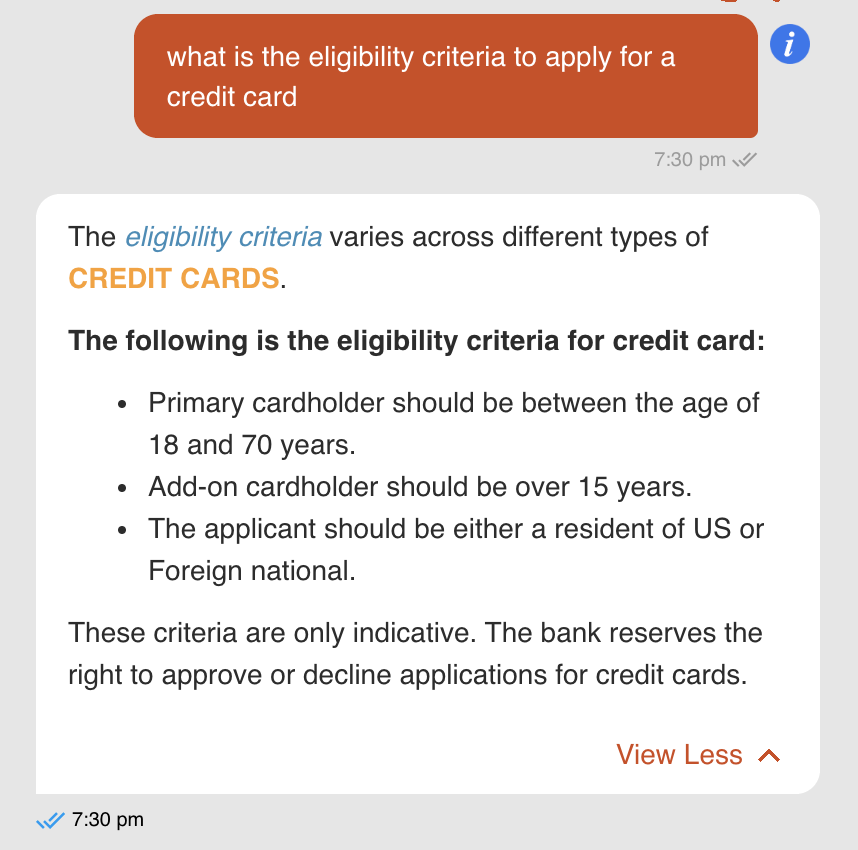
Sample response text:
The Eligibility Criteria Varies across different types of Credit Cards.
Individuals eligible for Axis Bank Credit Card:
These criteria are only indicative. The bank reserves the right to approve or decline applications for Credit Cards.
F5 - Text response with CTA [1 or more]
F6 - response with quick links
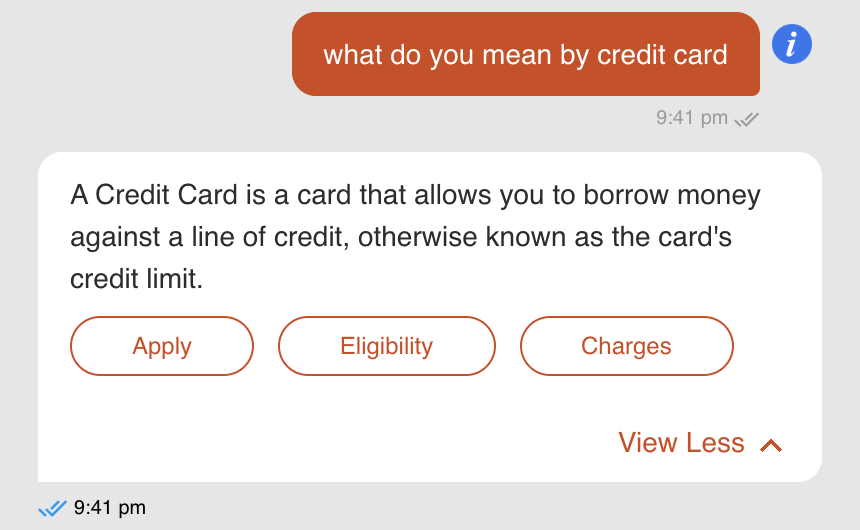

F7 - Text response with related questions embedded
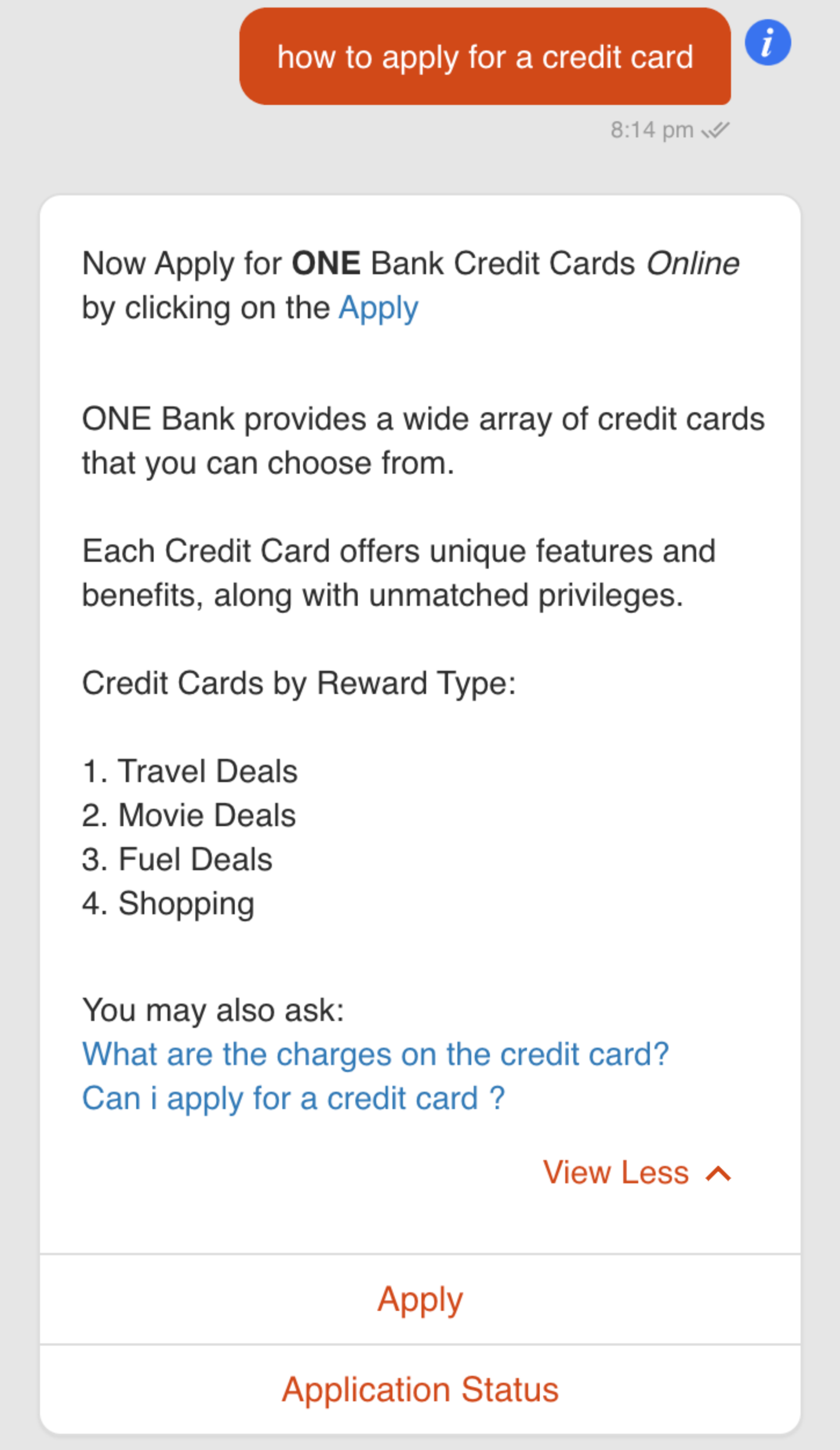
The following responses are curated using the in-built template editor feature, when response type is selected as 'Template'
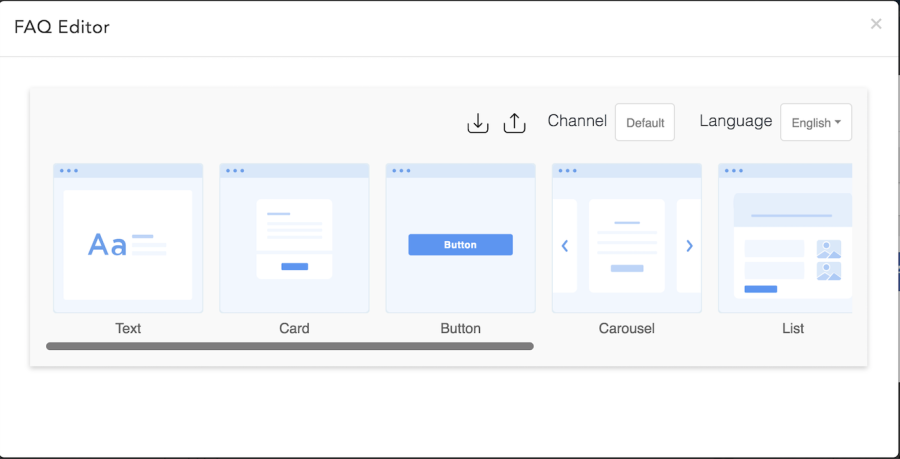
F8 - Card with button
F9 - Carousel
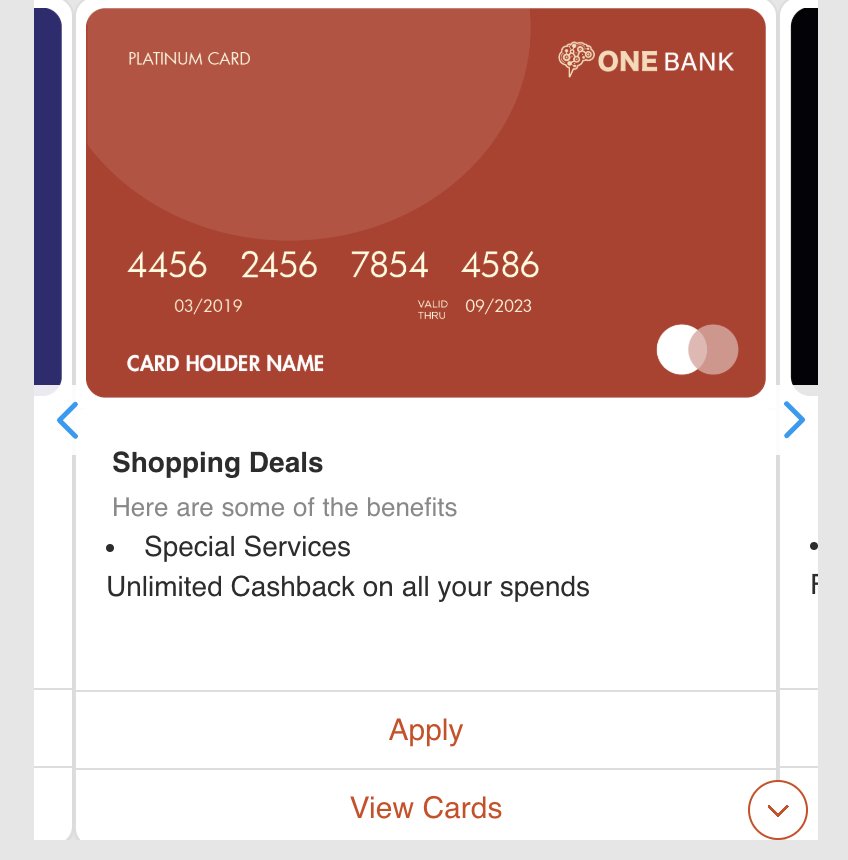
F10 - List
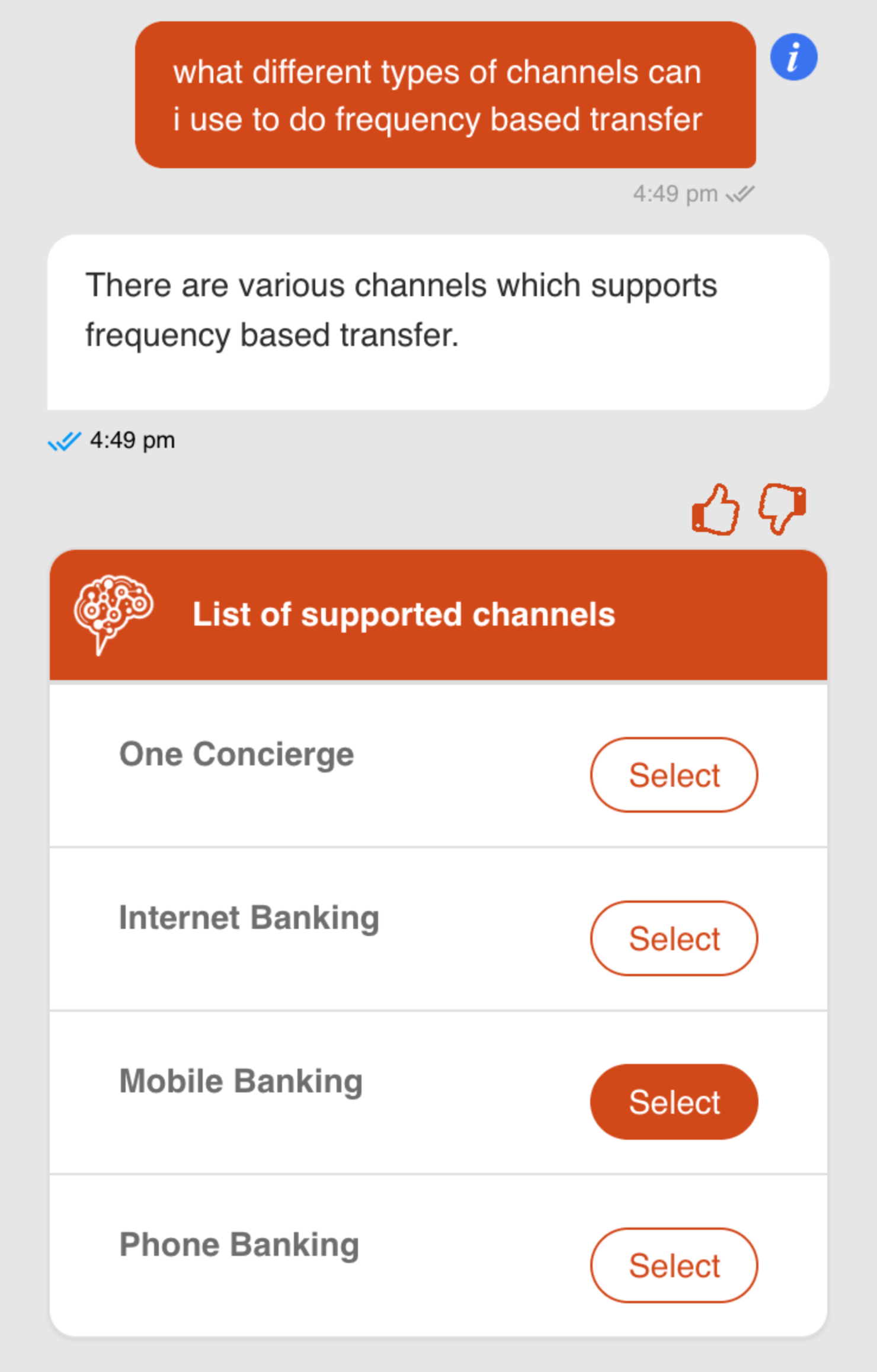
F12 - Combination
F 13 : Work-flow response
A Work-flow can be triggered (using the in-built WF editor) when user asks a process oriented question that involves a series of user actions to fulfill the answer.
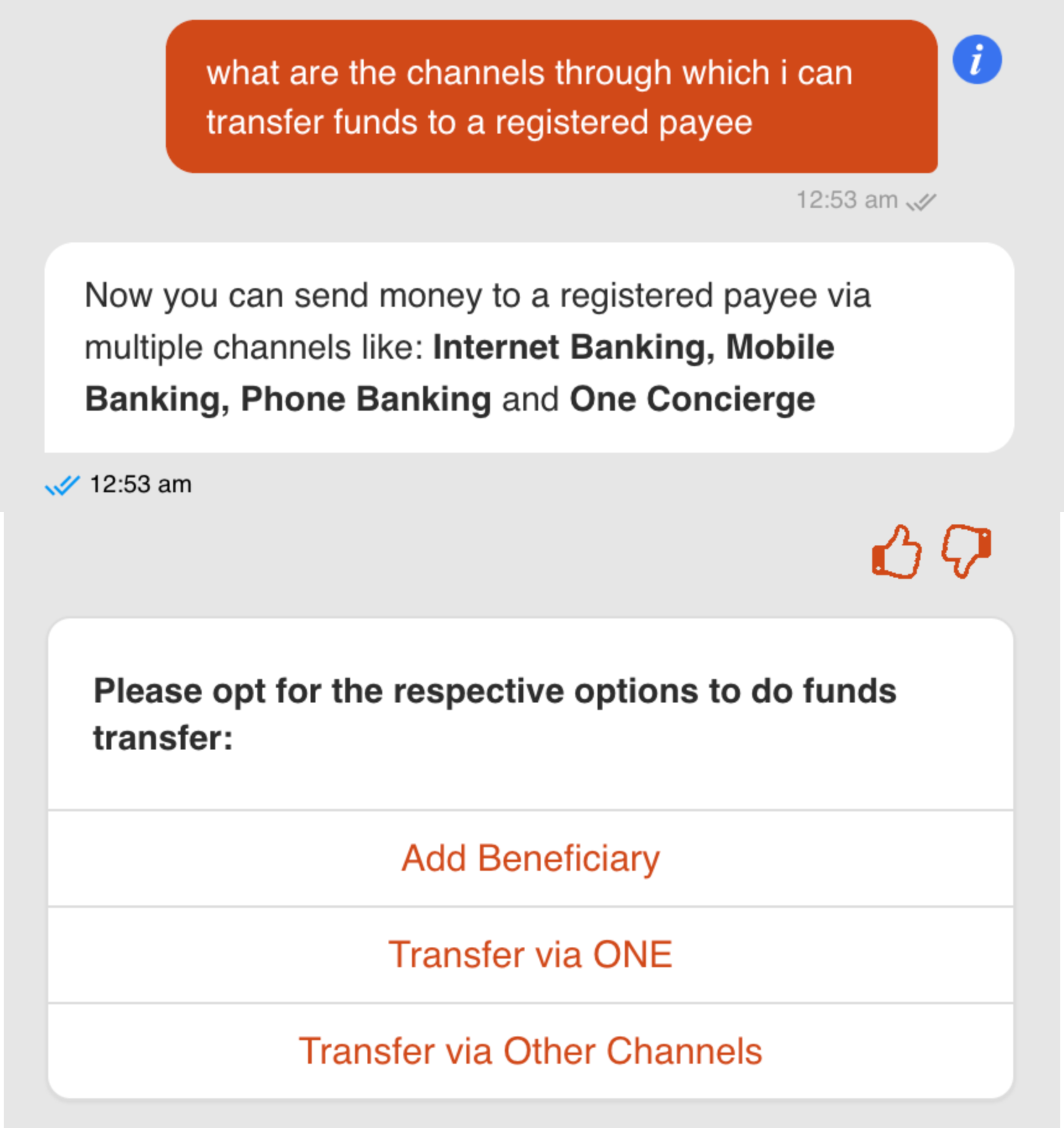


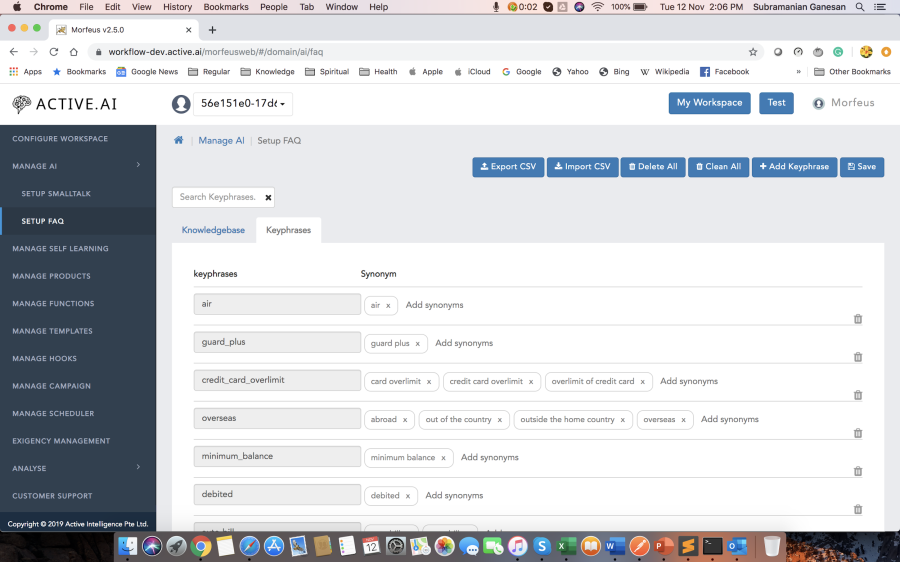
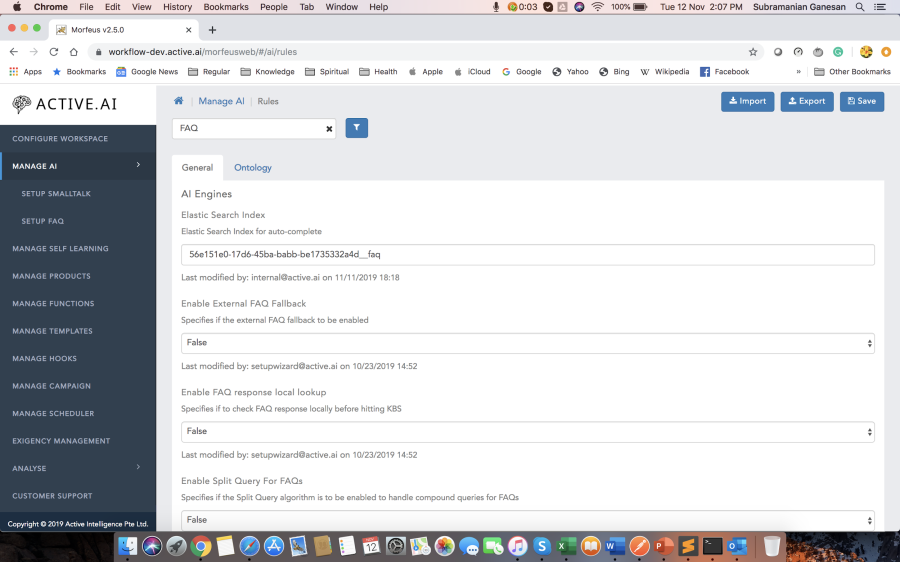
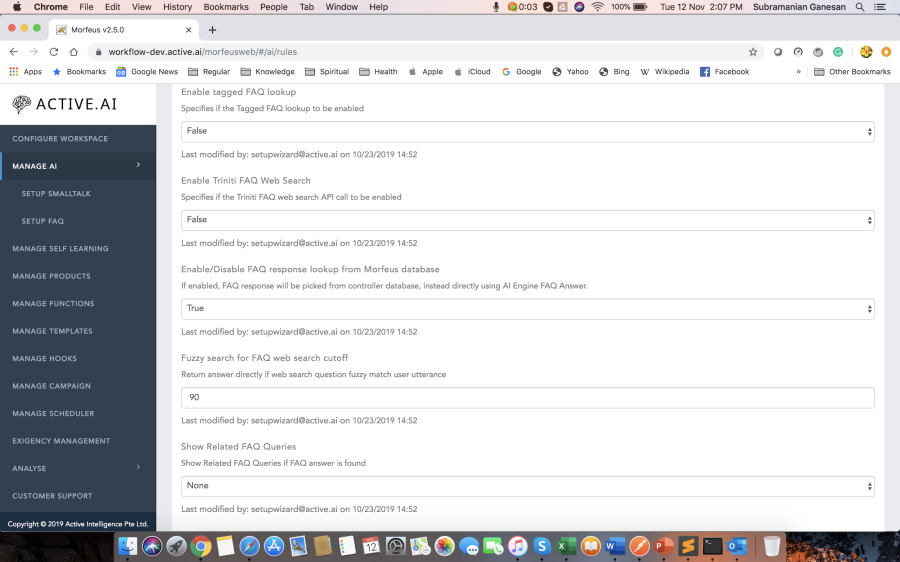
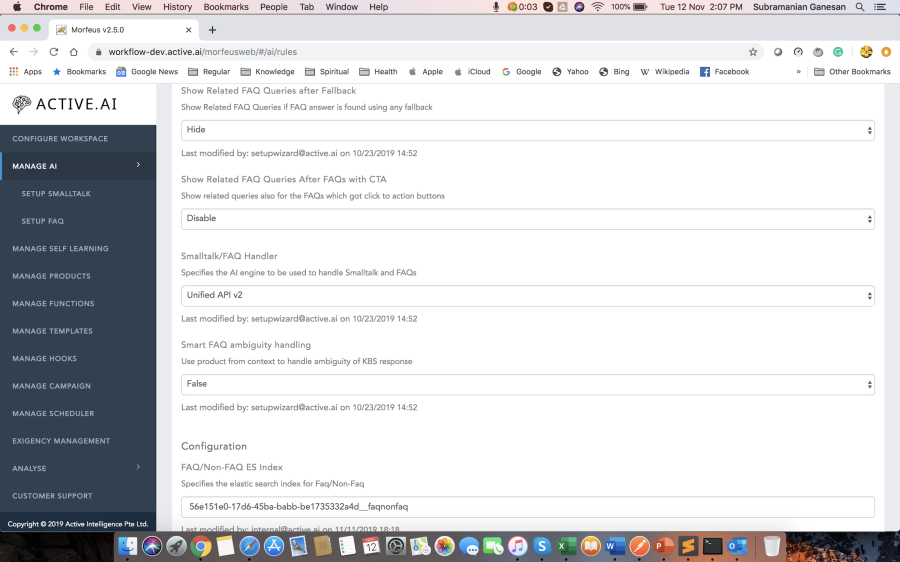
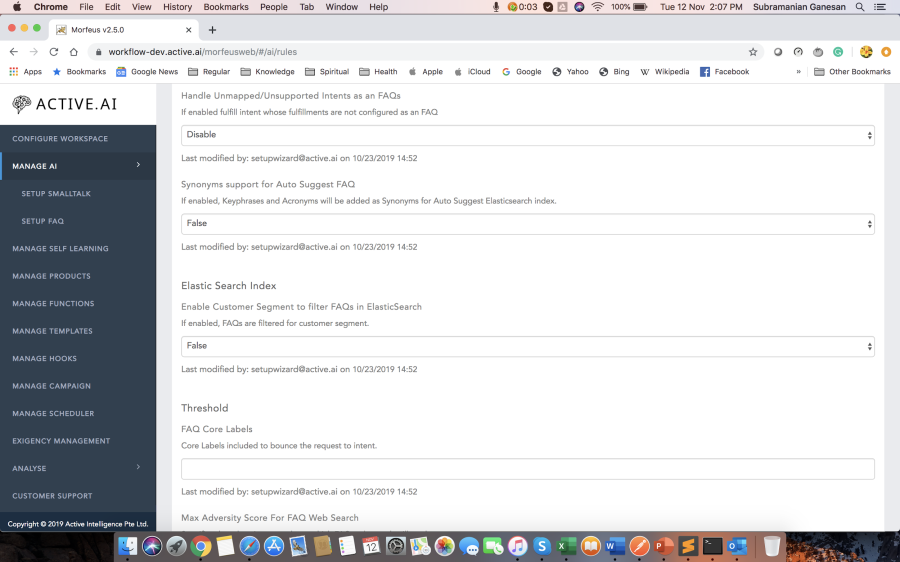
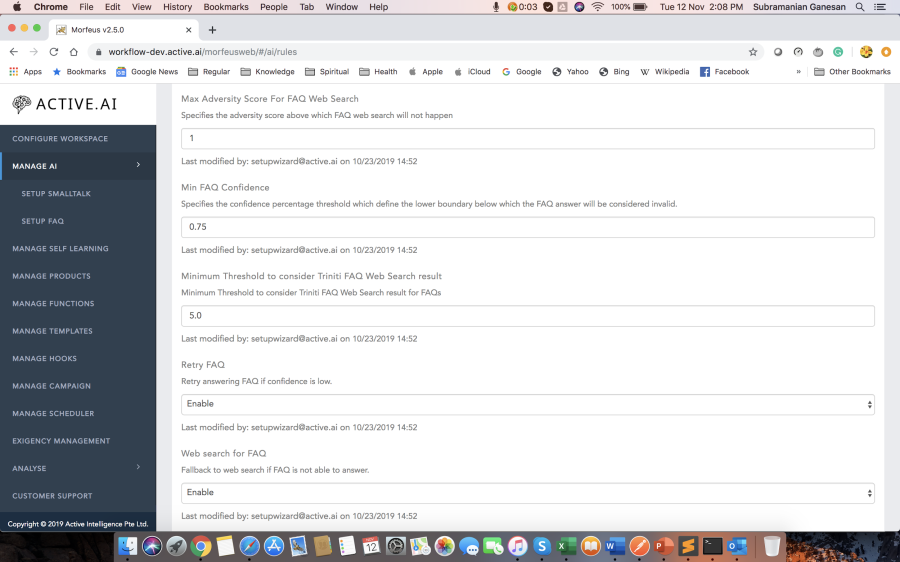
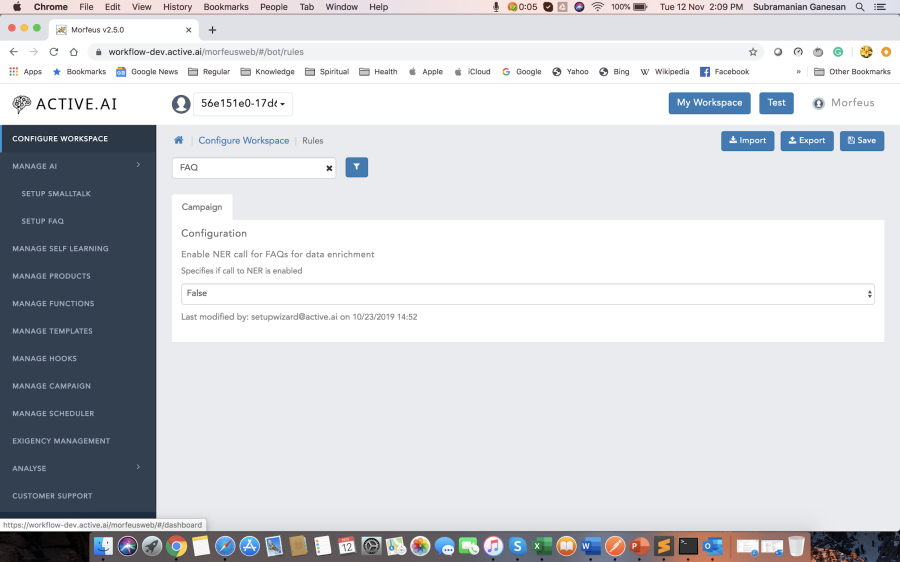
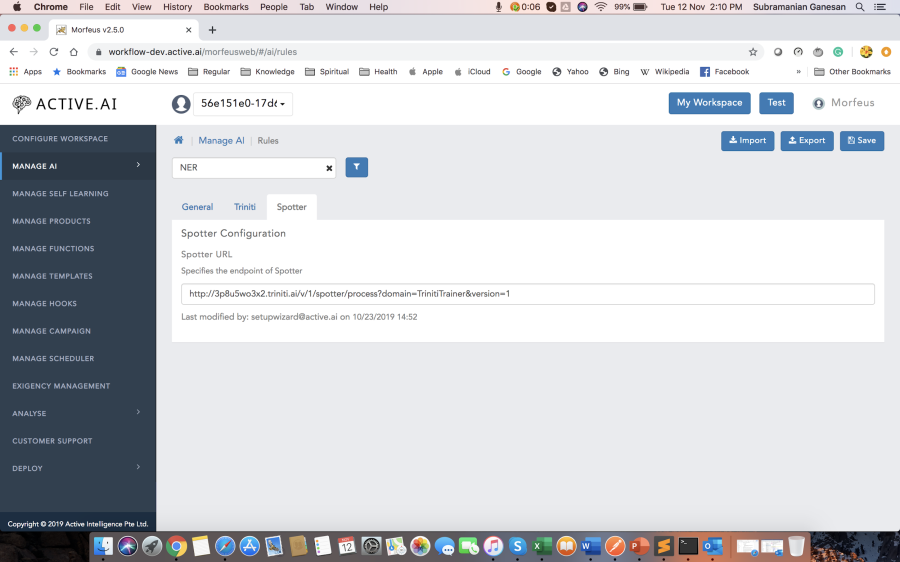
Linking FAQ to fulfillment
1) Navigate to Manage AI - Setup FAQ 2) Click on the FAQ for which Work-flow needs to be created. Refer below screen.
3) Select the Response Type as Work-flow, which will show a new button named as Configure Workspace 4) Click on Configure Workspace.
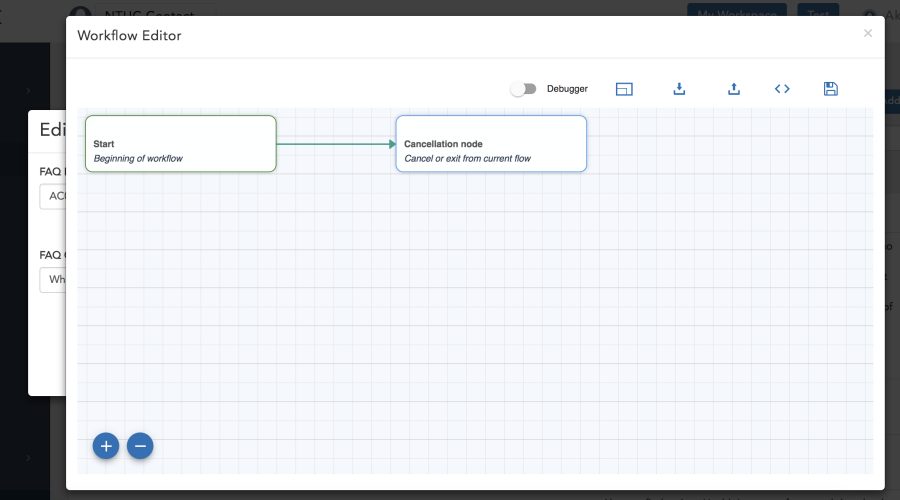
5) User can setup the Work-flow as per his business requirement. 6) To add a node, click on add symbol on the node.

7) Click on the settings icon to configure the node. 8) Node configuration mainly consists of 3 components..
a. Definition: This category contains the following keys (as can be seen from the attached fig below) :
Node name: name of the node. Node description: a brief description of what the node does. Entities: The entity to be handled by the node. Keyboard State: A hint to the client SDK what kind of input is expected from the user. Prompt: Messages to send to the user to ask for the entities.
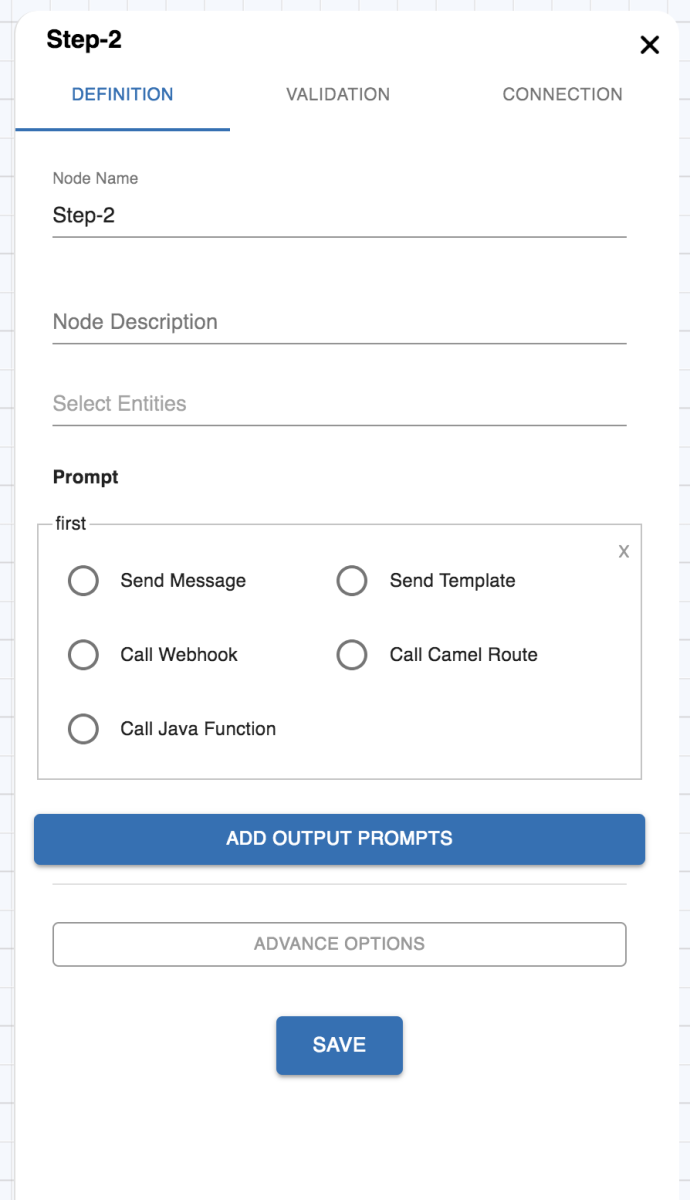
Prompt Message: There are various ways to send the output message. Listed below:
1) Send Message: This will allow a static message from the given node.
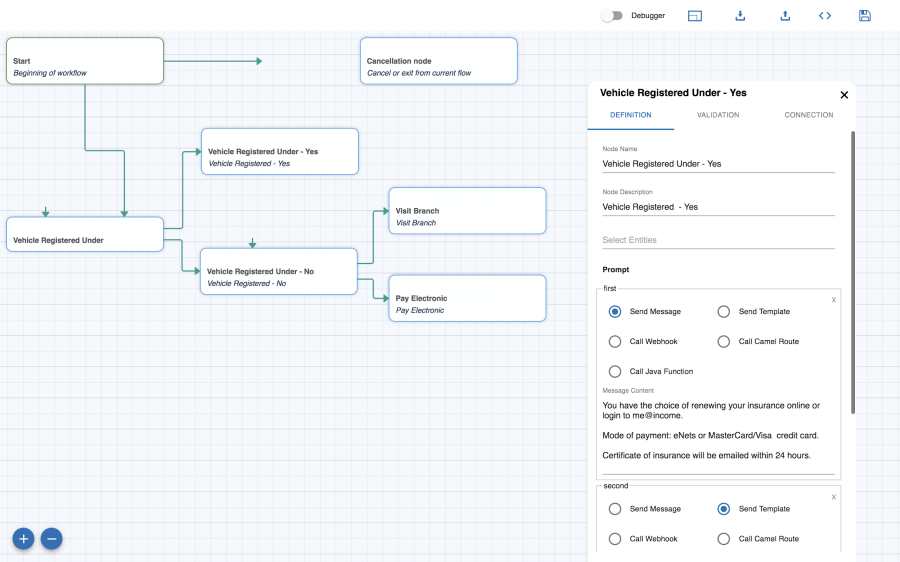
2) Send Template: This will be used for creating dynamic templates. Below are the steps to create template.
- Click on Send Template radio button which will bring a Create Template Button.
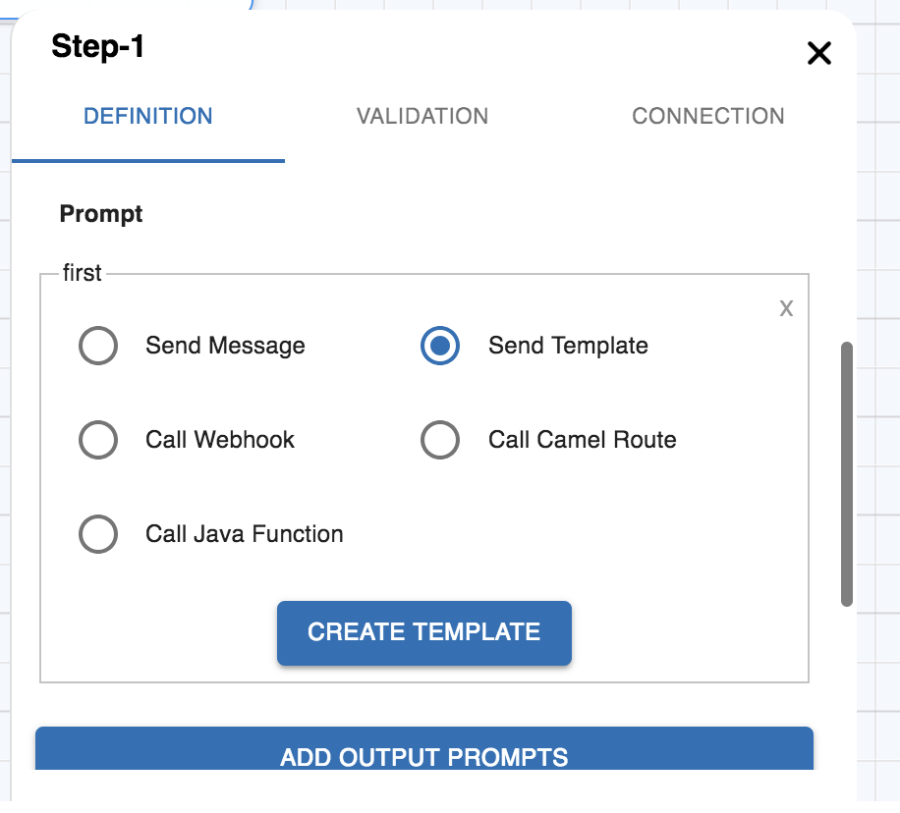
- Click on the Create Button, which will show up the template editor view with options to create templates of different types i.e Text, Card, Button, Carousel, List and Image.
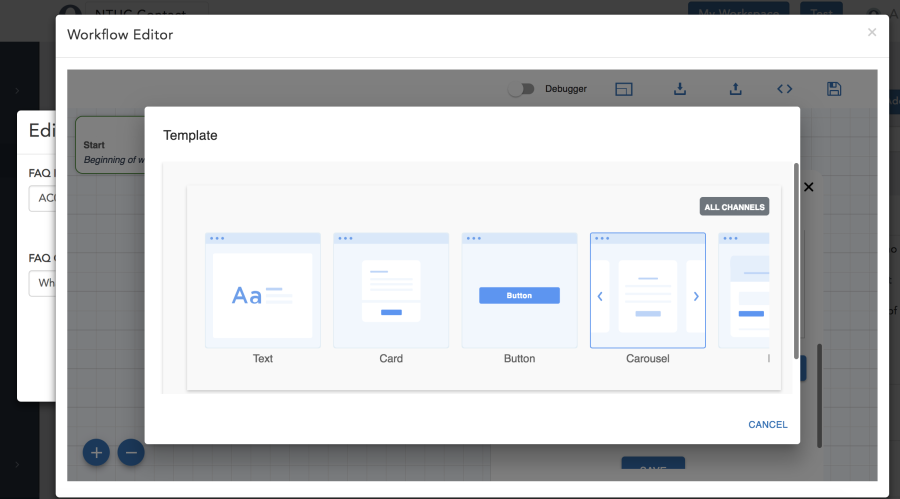
- Click on the required type of template, which will ask for further information. In addition you can add Quick reply to any of the templates.
Different types of Templates:
Text:
This will allow you to create a text template with options to add a quick reply to it if required.
Card:
This will allow to create a template with image, title , subtitle and button.
Button:
This will allow to create a template with text and button in it.
Carousel:
This will help in creating a carousel template where in you can configure image, title , subtitle. You can add items as required by clicking on the add  icon given at the below screen.
icon given at the below screen.
List:
We can create a list template by filling in the required information. To add a new item, click on + ADD ITEM
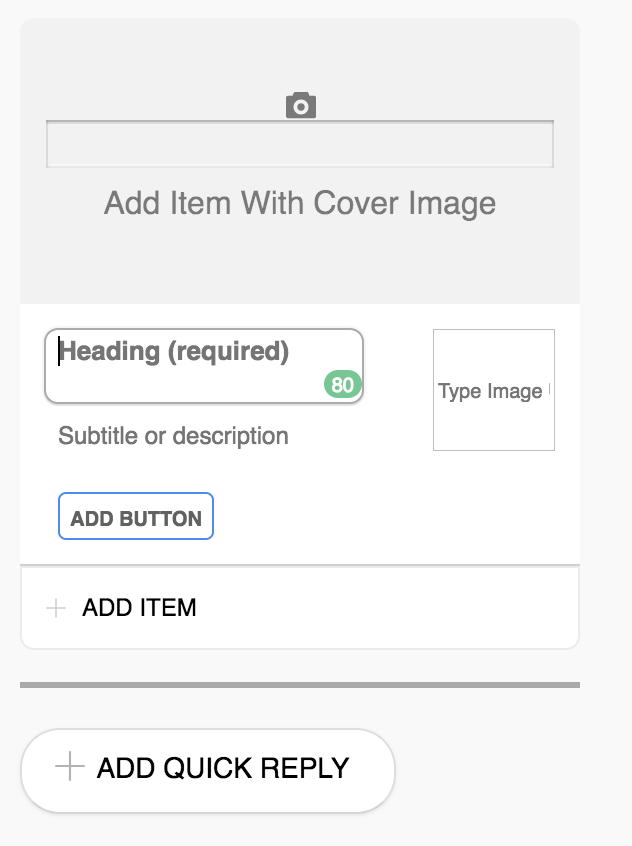
Image:
This allows us to create an image template wherein we need to provide a valid image URL and the same will be reflected in the template.
Steps to configure button of different types: There are two types of button one is postback and the other is external url. To add a button, click on the + ADD BUTTON, which will bring the button configuration popup.
Note that the button configuration remains the same for all types of templates.
1) Payload: We will have to provide the button title and the required payload which will be sent to the backend server. Click on the postback tab to add required data. Example for payload data is: {"data":{"options":"Yes"}, "intent": "intent-name"}
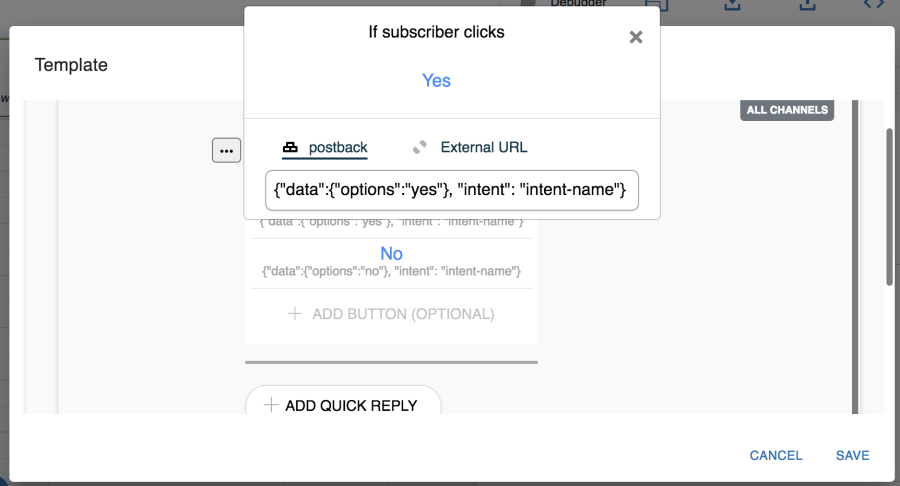
2) External URL: This is the button which allows user to redirect to an external website. Add the required button title and external URL.
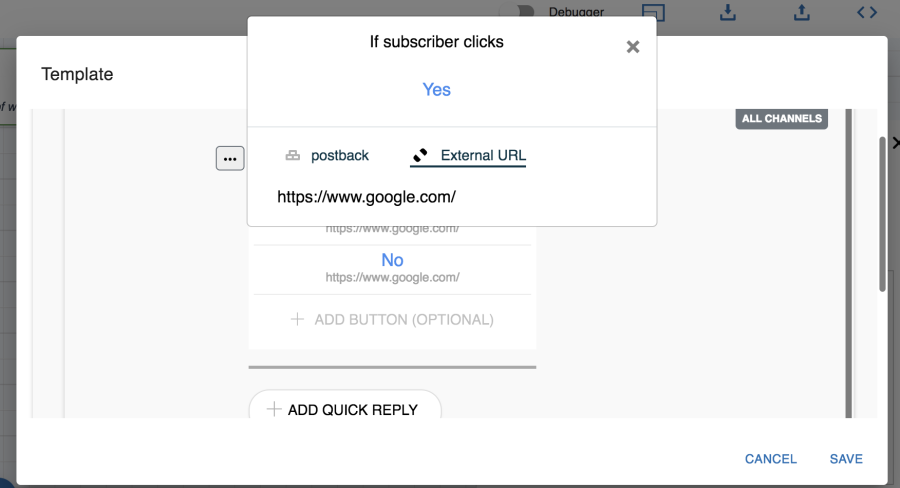
b. Validation: This category contains the keys participating in the validation of user inputs:
Validation Type: defines the type of validation of the user inputs e.g. regex validation, camel route validation etc.
Login session required: if checked, the key secured in JSON is set to true, meaning that the user will have to be logged in as part of validation for this node.
End flow if Validation Fails: if checked, the flow will end altogether in case the validation of the current node fails.
Error Prompt: this static error text message is displayed if the user fails the validation. This error message will be added in outputs[] of the JSON with "id"="error".
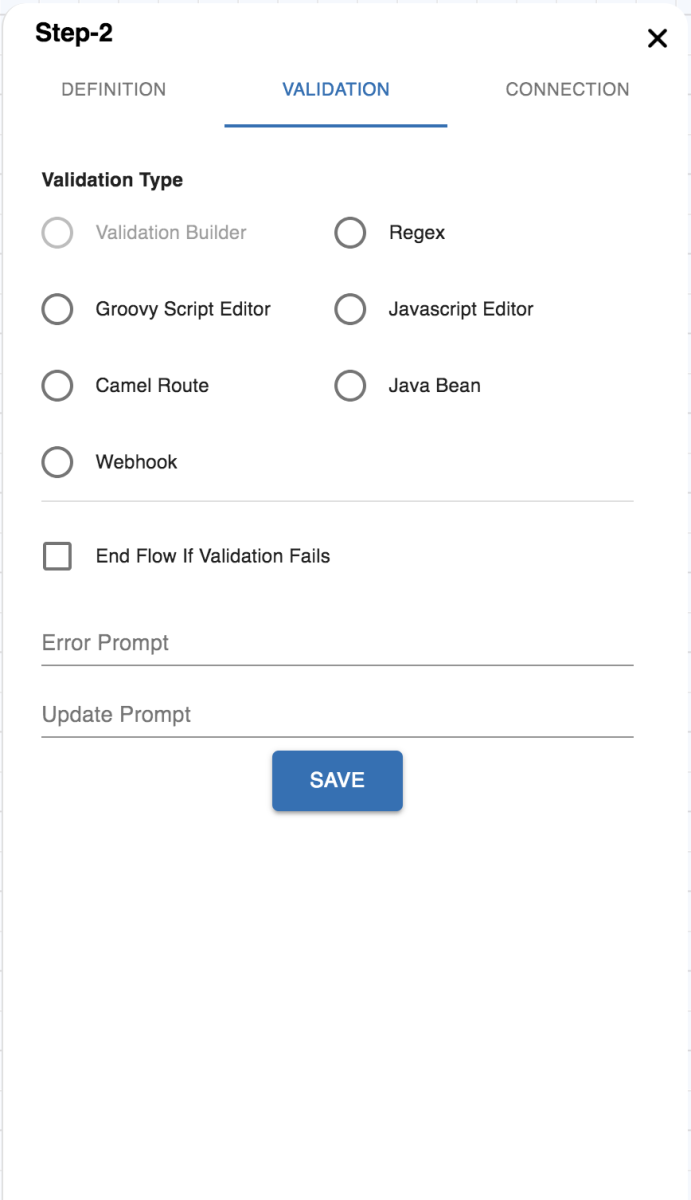
c. Connection: This section can be configured to have conditional branching to another node and is reflected in the script section of the input definition in JSON.
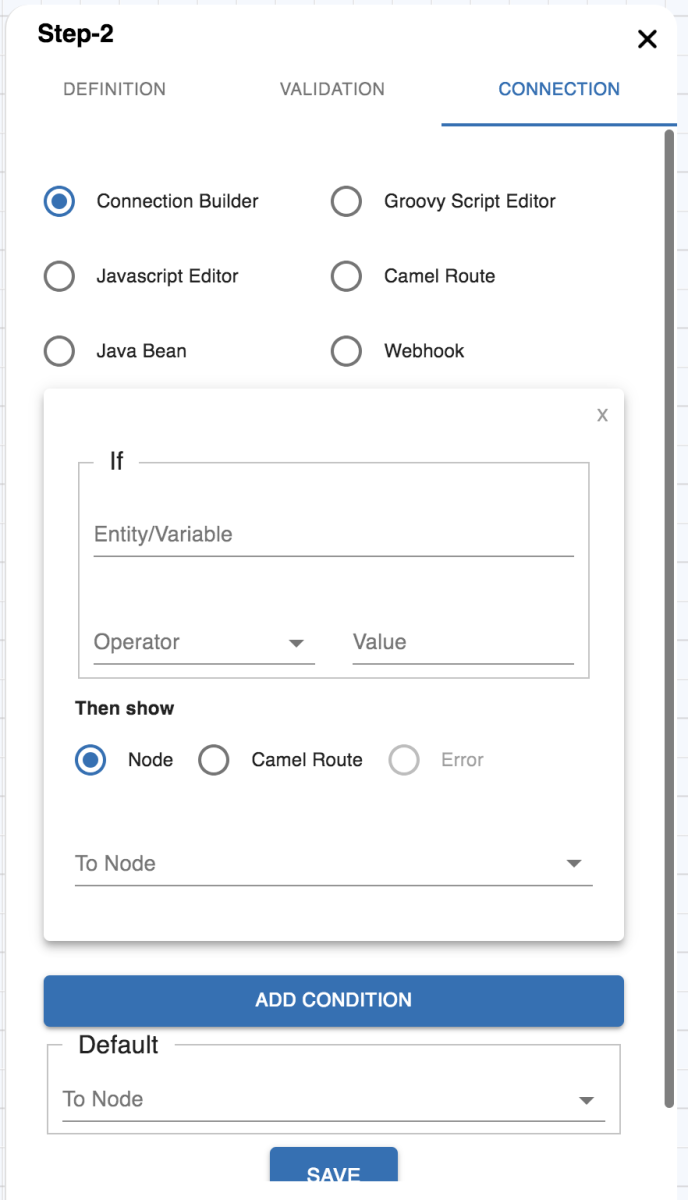
Connection builder setup example for the buttons with Yes/No as payload data:
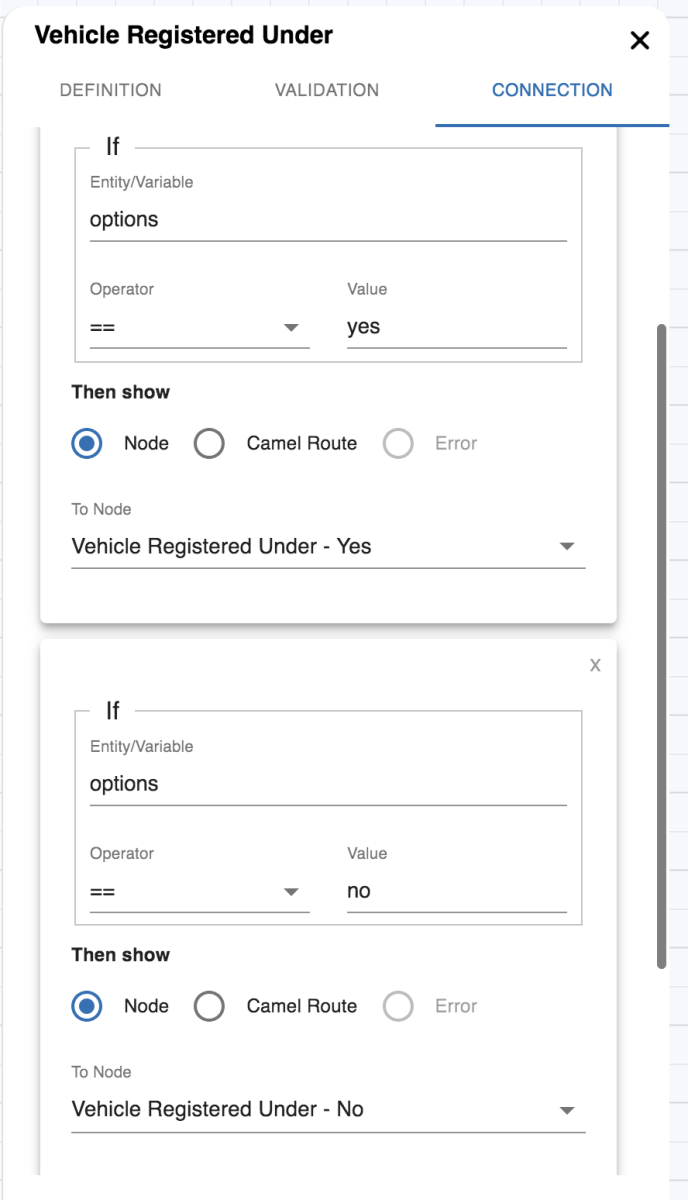
Once the Work-flow setup is done, click on the Save icon at the top right corner to save it.
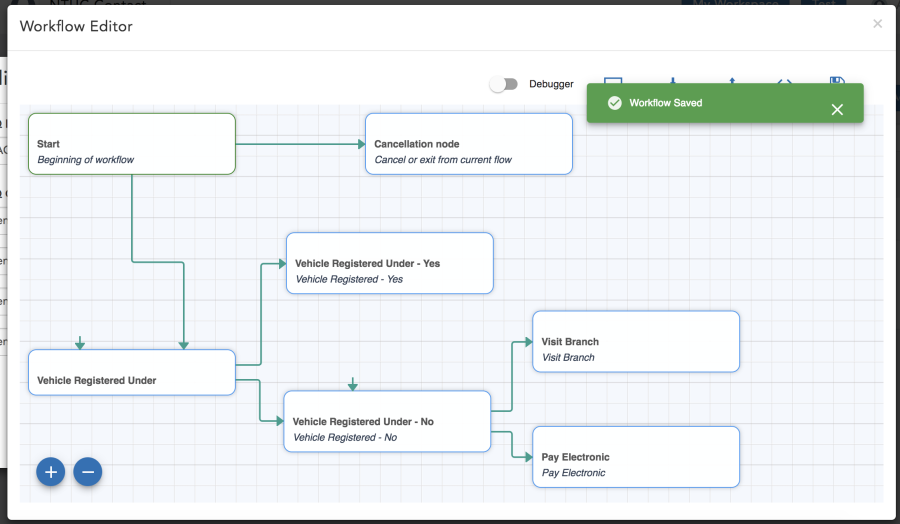
How to call Work-flow from a template /node:
Please use the below format to call any existing Work-flow from a button click or list.
Format:
{"data": {"FAQ": "<
Example:
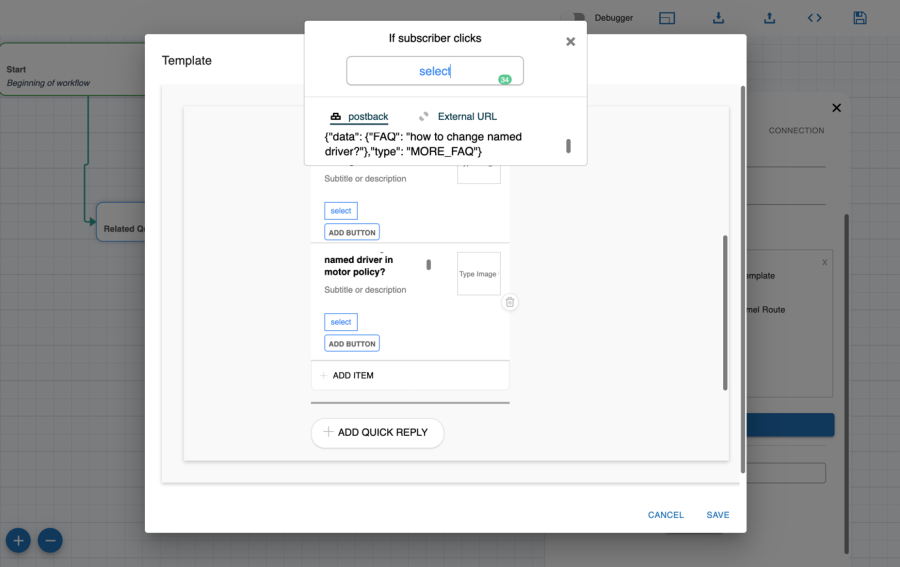
Advanced Configurations
Auto suggest corpus variants
This will help to configure if the auto-suggested FAQs need to come from entire corpus including variants or only the main FAQs

- Main - only unique FAQs are considered for auto suggestions
- All- Suggestions could include variants too
Auto Suggestion index
This configuration controls the automatic suggestions that follow once the user's question has been responded.
Show related FAQ queries
Multi Lingual FAQs
~Coming Soon~
Ancillary features
~Coming Soon~
Bot Design
Simply upload your logo (Specs here) and enter your preferred colours to customise the look and feel of the bot. You can also select a style here.
Bot Messages
You can customise your bot welcome, good bye, error messages here.
Channels
Enabled/Disable one or more channels below and configure them.
Facebook [configure]
Web [Integration guide]
If you want to integrate the chatbot on your mobile application(iOS/Android). Please use the SDK and instructions provided here.
Going Live
If you are training and testing a free workspace, you have a couple of ways you can go live to public.
1. Upgrade the workspace to paid workspace with appropriate billing plans/limits.
2. Create a new paid workspace and import data and settings from the free workspace.
We recommend the second option so that you can keep a stable workspace that is live. While you continue improvements and testing on the free one.
Lead Generation
By enabling this feature the chat bot can handle request to apply for new products, capture some basic information and forward it to you via email or you can configure a restAPI/webhook.
Simply provide the products that they can apply for, Select what information you would seek from the user and we will take care of the rest.
Name : Mandatory
Phone Number : Optional
Email : Mandatory
Product Type : Mandatory
Product : Optional
Did you know ? You can suggest the user to apply for the product from related FAQs. Find out how here
Live chat
You can enable the ability for customers to reach Live Agents.
Select one of the Pre-integrated Service providers below and configure.
Select when you want the live chat to be triggered automatically.
[ ] if unable to answer a query 2/3 times consecutively.
[ ] If user is unhappy 2 times.
[ ] if user uses profanity 2 times.
User queries
You can also look at the individual queries that users are asking. The list is sorted by time with latest on top. Repeated entries are rolled up with a count shown.
Queries that might need your attention are highlight in amber. You can simply click on the entry and make correction to the way it was handled. Or you can simply click ignore if the handling was right and we won't highlight this in the future.
Incorrectly handled queries can be fixed in few ways.
a. Point it to the right FAQ question
b. Add this as new smalltalk / FAQ
c. Point it to the right intent (Lead Generation / Live Support)
d. Block it with a Message based on a keyword used.
Knowledge Graph
A knowledge graph is a hierarchical mapping (Tree Structure) of the products and services an enterprise has to offer for customers.
AI Classifiers are probabilistic by nature, so they may not be best suited for short 2-3 word utterances. Knowledge Graph provides a deterministic alternative with configurable probing in case of ambiguity.
Debugging & Troubleshooting
Debug AI
Debug Data
Debug Flow
Manage Deployments
Overview
Deployment helps to manage the Morfeus Middleware, AI data training lifecycle. Currently we support 2 kinds of deployment workloads.
- Local deployments (On-Prem)
- Cloud Deployments
This feature also keeps track of AI data trained & deployed previously. These trained data models can be restored at a later time. Every AI data training is identified by data Id (GUID - 32 byte Alphanumeric string)
Local deployments
For Morfeus deployment, please follow the below link. ~Coming Soon~
On-prem trainer and worker setups should follow the local documentation setup. AI trainers and AI worker processes should be configured as below.
Components
| Table 12 AI trainers and AI worker processes' Configurations | |
|
Rules
|
Description
|
|---|---|
| Triniti Trainer | AI engine performing base classification, natural language understanding, Named Entity recognition, spell checking and generates AI models specific to AI data domains & AI data provided. |
| Triniti Worker | AI process which will be loaded with the AI models and answers the user utterances from the chatbot. |
| Spotter Trainer | Deep learning AI engine generating supervised and unsupervised FAQ models. |
| Spotter Trainer | AI process loads the deep learnt model for serving the user queries related to FAQs. |
| Manager | Process helps to manage, interface and maintain all the trainers & workers with middleware through APIs. |

Rules for local deployments
| Table 13 Rules for local deployments | ||||
|
Configuration Type
|
Rule Name
|
Rule Location
|
Description
|
Example
|
|---|---|---|---|---|
| Deployment Type | Deployment Type |
|
Decides local/cloud deployment | local should be choosen |
| Manager Process | Triniti Manager URL | Manage AI → Manage Rules → Triniti | Manager URL (Contains config information related to Triniti / Spotter Masters) | http://10.2.3.12:8090/v/1 |
| Triniti Master |
|
|
Configured in Manager |
|
| Spotter Master |
|
|
Configured in Manager |
|
| Triniti Worker processes 1..N | Unified API v2 process used only when loading after successful data training | Manage AI → Manage Rules → Triniti Unified Api V2 | Comma separated URLs. Format: scheme1://host1:port1,schemeN://hostN:portN | http://10.2.1.24:8003,http://10.2.1.24:8004 |
| Triniti Worker Nginx URL | Endpoint URL | Manage AI → Manage Rules → Triniti Unified Api V2 | Serves the request from the bot, either can be configured as the process itself, if we have only 1 worker. If multiple workers available, then a web server is needed for load balancing requests. | http://10.2.1.24:8008 |
| Spotter Multi Tenant Worker Processes 1..N | Spotter worker process used only when loading after successful data training | Manage AI → Manage Rules → Spotter | Comma separated URLs. Format: scheme1://host1:port1,schemeN://hostN:portN |
|
| Spotter Worker Nginx URL | Spotter URL | Manage AI → Manage Rules → Spotter |
|
http://10.2.1.24:8006 |
Workspace Type : Conversational Bot - Both (Triniti + Spotter)
Triniti worker forwards requests to Spotter worker in case of FAQs/Smalltalk
Workspace Type : FAQ Bot
Spotter Only FAQ bots will use spotter workers for serving the response
Worker loading process
- Manager should be configured with the Masters configurations (Triniti, Spotter master server configuration)
- Train AI data from admin & loading is supported by 2 ways (Automatic & Manual)
- Automatic loading: Successful train will automatically trigger a load
- Manual loading: Select Data Id in Deploy → Deployments → Select Data Id → Deploy Button

Worker load processes states

| Table 14 Worker load processes states | ||
| State | Description | Action |
|---|---|---|
| SUCCESS | Successfully loaded the model with the specified data ID |
|
| FAILURE | Load failed for the specific worker | Check the worker logs for the reason of Failure and retry loading |
| LOADING | In-progress of loading | |
| PENDING | Already a loading of another process is on-going. Once done the next process loading will start automatically |
|
Troubleshooting steps
- If loading is not complete with 10-15 minutes, then there is a possible issue
- Admin didn't receive any callback from manager about the loading
- Possible network error (Manager ↔ Process or Admin ↔ Manager)
- Clear the Redis key (Key: ONPREM:
retry loading
- Manual intervention needed when there is connectivity issues between admin and worker processes
- Manual intervention needed when the process struck in loading state for more that 10 minutes (especially Triniti)
- In above cases, connect to Redis temporary store and delete the key (ONPREM:
) to reload the process
Cloud Deployments
Cloud deployments are facilitated by a mandatory component Manager. Morfeus, Triniti Trainers & Workers, Spotter Trainers & Workers can be launched using cloud deployments.
Set Manage AI Rules
For enabling cloud deployments, please set the below rules, to proceed with using and launching the deployment workloads.
Navigate to Workspace → Manage AI
| Table 15 Manage Ai Rule configurations | ||
| Category | Rule | Value |
|---|---|---|
| General | AI Engine | UnifiedApiV2 |
| General | Primary Classifier | UnifiedApiV2 |
| General | Entity Extractor | UnifiedApiV2 |
| General | Smalltalk/FAQ Handler | UnifiedApiV2 |
| General | Context Change Detector | UnifiedApiV2 |
| Triniti | Deployment Type | Cloud |
| UnifiedApiV2 | Triniti | Triniti Manager URL |
| UnifiedApiV2 | Endpoint URL | https://router.triniti.ai |
| UnifiedApiV2 | Unified API Version | 2 |
| UnifiedApiV2 | Context Path | /v2 |
Set Workspace Rules
- Select Workspace, Navigate to Configure Workspace → Manage Rules
- Navigate to Security tab and set Access Key ID & Secret Access Key
- Navigate to Configure Workspace and set preferred Language and Country
- Click Save
Create Instances
Start Morfeus Instance
- Select Workspace, Navigate to Deploy → Infrastructure-> click Morfeus tab
- click Add Morfeus Instance
- Select Base OS, Server Type and JAR Artifactory folder path
- The content in the JAR Artifactory Path will be loaded in the class path of the Application container (Tomcat/JBoss)
- Upload the morfeuswebsdk and web view wars in the artifactory URL
- All integration jars will be placed in the container's class path and WARs will be uploaded in the deployment path (ex: Tomcat - webapps / JBoss - deployment)
- All other files (Ex: .properties, .json, .txt etc will be placed in /opt/deploy/properties folder in the container
- ApiKey for the Morfeus container need to be updated in js/index.js of the Morfeuswebsdk.war
- For xAPIKey reference check Customisable features in Web-sdk.
Start Triniti/CongnitiveQnA/Both instance
Users can create Conversational AI (Triniti) Instances, CognitiveQnA (Spotter/Faqs) Instances or Both
- Select Workspace, Navigate to Deploy → Infrastructure-> click Triniti tab
- click Add Triniti Instance
- Select Base OS, Data ID and Language
- Data Id will be the reference of the training done through AI Ops

Update Instances
- Select Workspace, Navigate to Deploy → Infrastructure
- Select desired server Morfeus tab (or) Triniti tab to update the Time-To-Live
- Default Time-To-Live for any Instance created will be 120 Minutes (2 Hours)
- Maximum Time-To-Live can be 24 hours (1440 Mins)
- Triniti trained data models can be updated by selecting the new Data ID while updating instance
- click Update
Delete Instances
- Select Workspace, Navigate to Deploy → Infrastructure
- Navigate to the instance Morfeus or Triniti
- Click Delete Instance
After Time-To-Live (in Mins), the Instance will be shut down automatically. Users can delete the instance before this Time-To-Live period.
Restart Instances
- Select Workspace, Navigate to Deploy → Infrastructure
- Navigate to the instance Morfeus or Triniti
- Click Restart Instance

Use case: Refreshing Jar Artifactory Path for Morfeus Instances. This operation will restart the Server Container.
Guidelines
- A workspace can have only a single type of Instance (Either Triniti / CognitiveQnA / Both)
- Default Time-To-Live for any Instance created will be 120 Minutes (2 Hours)
- The Instance will get deactivated after 2 hours of non usage
- To start up the instance go to Deploy → Infrastructure section - Start Morfeus / Triniti
- Kibana URL provided in the instances information used for viewing log information
- Log Time period can be changed in Kibana UI for desired log time range
- Contact Admin in case of any issues when creating instances
Train
For AI data training follow these steps:
- Goto your workspace
- Navigate to 'Deploy'
- Click on 'Deployment'
- Select the data Id for which you want to train
- Click on 'Train'
- Click on 'Yes' on the popup (Do you want to train your AI Model?)
Stop Train
If you have started the train and wanted to interupt the train to modify AI data and start a fresh train, then follow the below steps:
- Goto your workspace
- Navigate to 'Deploy'
- Click on 'Deployment'
- Select the data Id for which you want to stop the train
- Click on Stop train
Import Zip
You can also import the deployed data by following these steps:
- Goto your workspace
- Navigate to 'Deploy'
- Click on 'Deployment'
- Click on 'Import'
- Select a ZIP file from your system (Which contains FAQs, smalltalks, spellcheckers, dialogs, etc.)

Export Zip
If you want to reuse the generated or deployed data, so you can export those data. And can use as per your need. You can export either Deployed data or Generated data.
Exporting Generated Data
- Goto your workspace
- Navigate to 'Deploy'
- Click on 'Deployment'
- Select the data Id for which you want to export the data
- Click on 'Export ZIP'
- Select 'Generated'
- Select 'Version'
- Click on 'Export'
It will download a ZIP file containing dialogs, NER, FAQs, parseQuery, primaryClassifier, smalltalk, spellcheck, etc*
Modular Train Button
Train button is added at five modules
- smalltalk - Manage ai → Setup SmallTalk
- faqs - manager ai → setup faqs
- spellcheck - manage ai → setup spellchecker
- primary classifier - manage products → functions → select any one function → navigate to DATA
- entities - manage ai → setup entites.
Notes
All the generation and Training steps are in sync once we trigger the training from any of the above modules. The current status will be updated in each modules respectively. If it is in progress, the status will be present everywhere and no new training will be triggered until the one going on is finished.
Generic Validations
Following are the error scenarios for which validation added which is applicable for all the workspace type :-
- Error message will be shown if the wrong manager url is configured.
- When the task api is not called after creation of workspace and when we click on training.
- when we click on train without generating the data
Data Generation Validation (FAQ workspace type)
Following are the error scenarios for which validation added which is applicable for FAQ only the workspace type :-
If spellchecker data is not present in the workspace, then generation will fail with error message
- If minimum 15 faqs are not present then generation will fail with respective error message
- If any small talk is added, then minimum 5 must be present or else no small talk must be there.
- Incase the translation if faqs or smalltalk fail when data generation is in progress, then generation will stop.
- If native language rule is enabled and there is no data for non-english language then warning will be displayed to disable it, but the generation will proceed.
Data Generation Validation [RB+FAQ workspace type]
- If spellchecker data is missing then generation will fail.
- if dictionary type entity is missing, then generation will fail with error message.
- when no intents are not present, then generation will fail giving the respective message. Here minimum 2 intents are required.
- If no faq are present, then minimum 15 faqs required message is shown and generation is failed.
- if any small talk is added, then minimum 5 must be present or else no small talk must be there.
- Incase the translation if faqs or smalltalk fail when data generation is in progress, then generation will stop.
- If native language rule is enabled and there is no data for non-english language then warning will be displayed to disable it, but the generation will proceed.
Quick Train - generic validation
When Elastic search url is not configured for the workspace, then on click of quick train, validation message is shown to update the url.
Quick Train related changes
FAQ only workspace
On click of train, Load data to ES only.
RB FAQ workspace
On click of train, load data to ES and Train only Sniper
Recent Module Update on Modular Training
- This change is available for rbfaq workspace type only, since modular training is present for it only.
- There are five modules whose recent update will be kept in check, those are :- smalltalk, faqs, ner, primary classifier and spellchecker.
- Once on click of Train, if there is any changes done in the above module then the respective screen will be shown to user to select the training of the modules.
If user clicks on Train All modules, then from abive faqs and primary classifier will be changed and if Train only smallTalk is selected then only smalltalk will be trained. Once proceeded the complete data generation will start and post that training will be proceeded. Respective updates will be shown for the generation and training steps.
New screens changes is shown below.
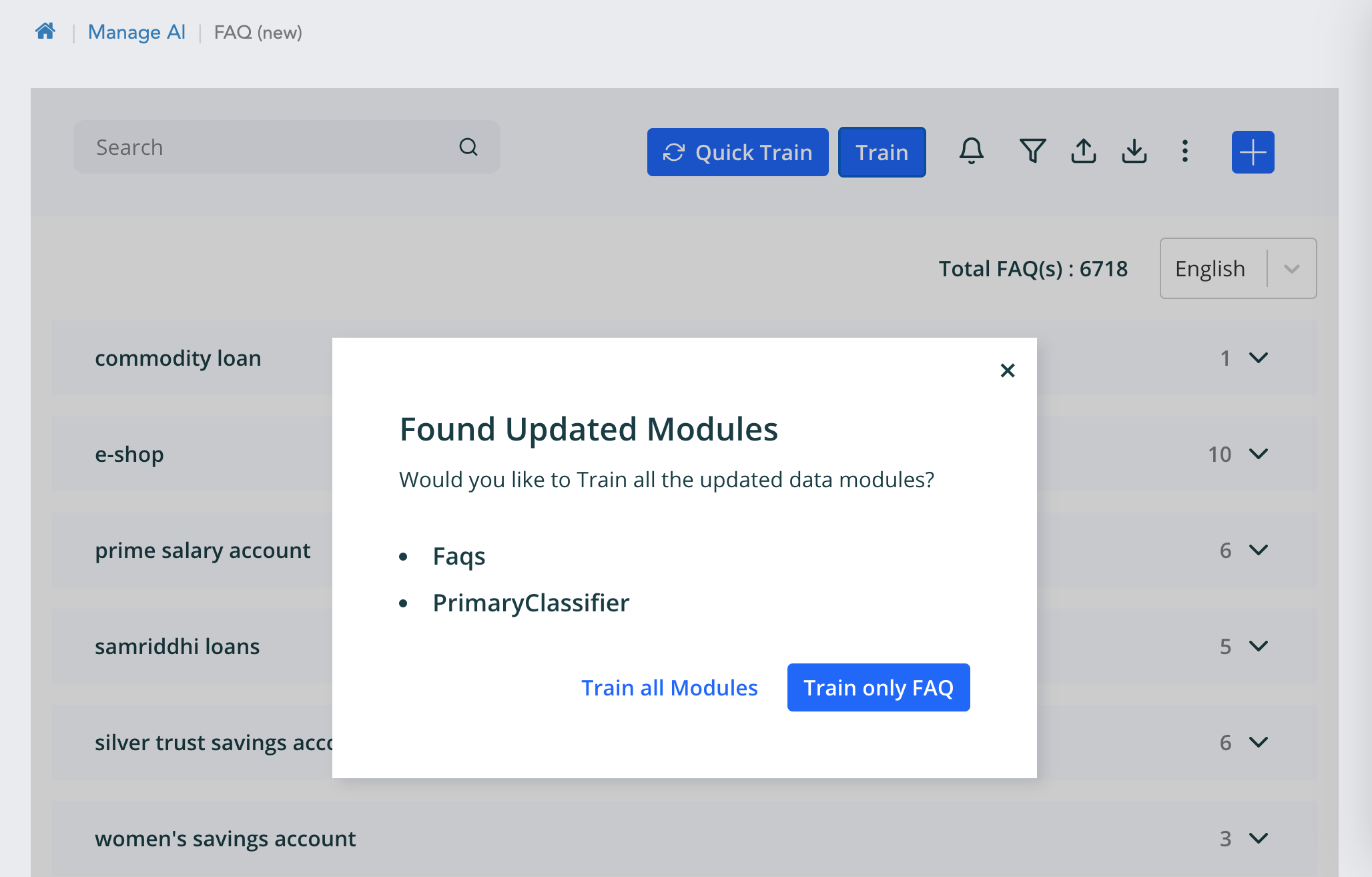
Note :-
Training triggered from any one of the five module, the training and generation status will shown on the remaining four modules.
This change is present on five modules and the Ai Ops Train button.
Sniper Base Model Selection
Definition
Base models are single models which are trained on curated on model training datasets guided from the large set of existing customer trained FAQs and variants. It is incorparated to incerease the expectation of accuracy of customer and reduce the false positive scenarios. All the models have been kept genetric in nature.Instead of having a signle model for a language, Sniper is now changed to work with multiple models for a language. This allows use to use base model sets for different situations. For example Tata Capital can have a different model from Axis Bank.
Configurations
Rules to configure are ->
Go to Manage AI -> Manage rules -> Cognitive QnA tab -> select any of the listed model inside the rule "Override Models for Sniper Config"
On data generation, the config.yml file is generated inside Cognitive QnA module which contains the Elastic search details having the username and password if configured in the workpsace rules. Having the elastic search rules enables, the sniper could connect direclty connect to ES.
TRINITI Version - 4.5
| Table 13 Rules for local deployments | ||||
|
Configuration Type
|
Rule Name
|
Rule Location
|
Description
|
Example
|
|---|---|---|---|---|
| Deployment Type | Deployment Type |
|
Decides local/cloud deployment | local should be choosen |
| Manager Process | Triniti Manager URL | Manage AI → Manage Rules → Triniti | Manager URL (Contains config information related to Triniti) | https://triniti45.active.ai/manager/v/1 |
| Classification Process | Triniti endpoint URL | Manage AI → Manage Rules → Triniti | Triniti URL (Contains config information related to Triniti) | https://triniti45.active.ai |
| Classification Process | Triniti context path | Manage AI → Manage Rules → Triniti | Triniti context path (Contains config information related to Triniti) | /v45/triniti |
| Triniti |
|
|
Configured in Manager |
|
Configuration
With Triniti 4.5 if you wish to make 2 separate calls for Triniti and Sniper. Configure the respective URL and context path for sniper and set the rule value KBS_CLIENT = spotter and TRAIN_VERSION = 4.5.



